Greedy based Value Representation for Optimal Coordination in Multi-agent Reinforcement Learning
{kind=link}
Abstract
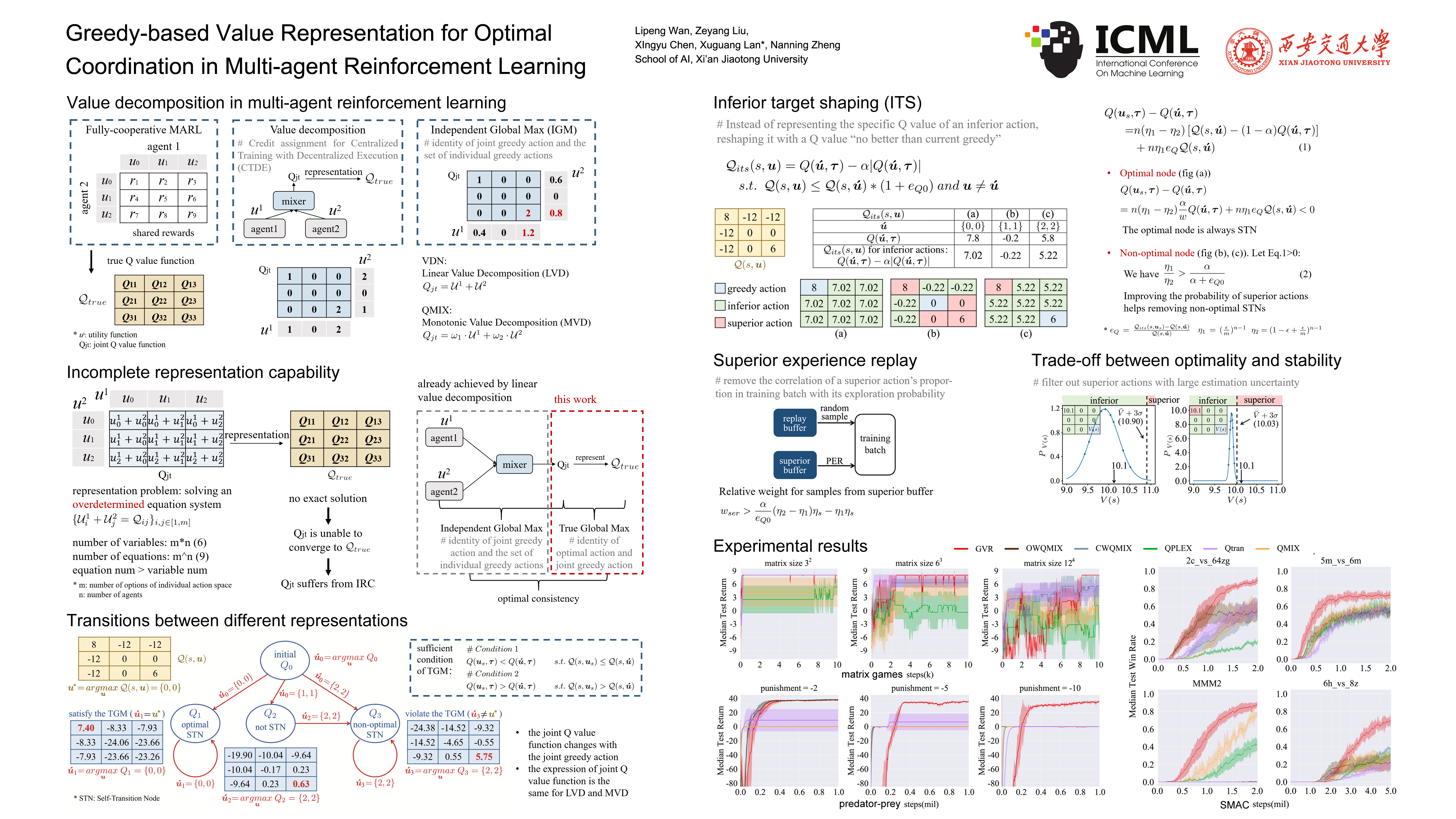
Due to the representation limitation of the joint Q value function, multi-agent reinforcement learning methods with linear value decomposition (LVD) or monotonic value decomposition (MVD) suffer from relative overgeneralization. As a result, they can not ensure optimal consistency (i.e., the correspondence between individual greedy actions and the best team performance). In this paper, we derive the expression of the joint Q value function of LVD and MVD. According to the expression, we draw a transition diagram, where each self-transition node (STN) is a possible convergence. To ensure the optimal consistency, the optimal node is required to be the unique STN. Therefore, we propose the greedy-based value representation (GVR), which turns the optimal node into an STN via inferior target shaping and eliminates the non-optimal STNs via superior experience replay. Theoretical proofs and empirical results demonstrate that given the true Q values, GVR ensures the optimal consistency under sufficient exploration. Besides, in tasks where the true Q values are unavailable, GVR achieves an adaptive trade-off between optimality and stability. Our method outperforms state-of-the-art baselines in experiments on various benchmarks.