Pretraining a Neural Network before Knowing Its Architecture
{kind=link}
Abstract
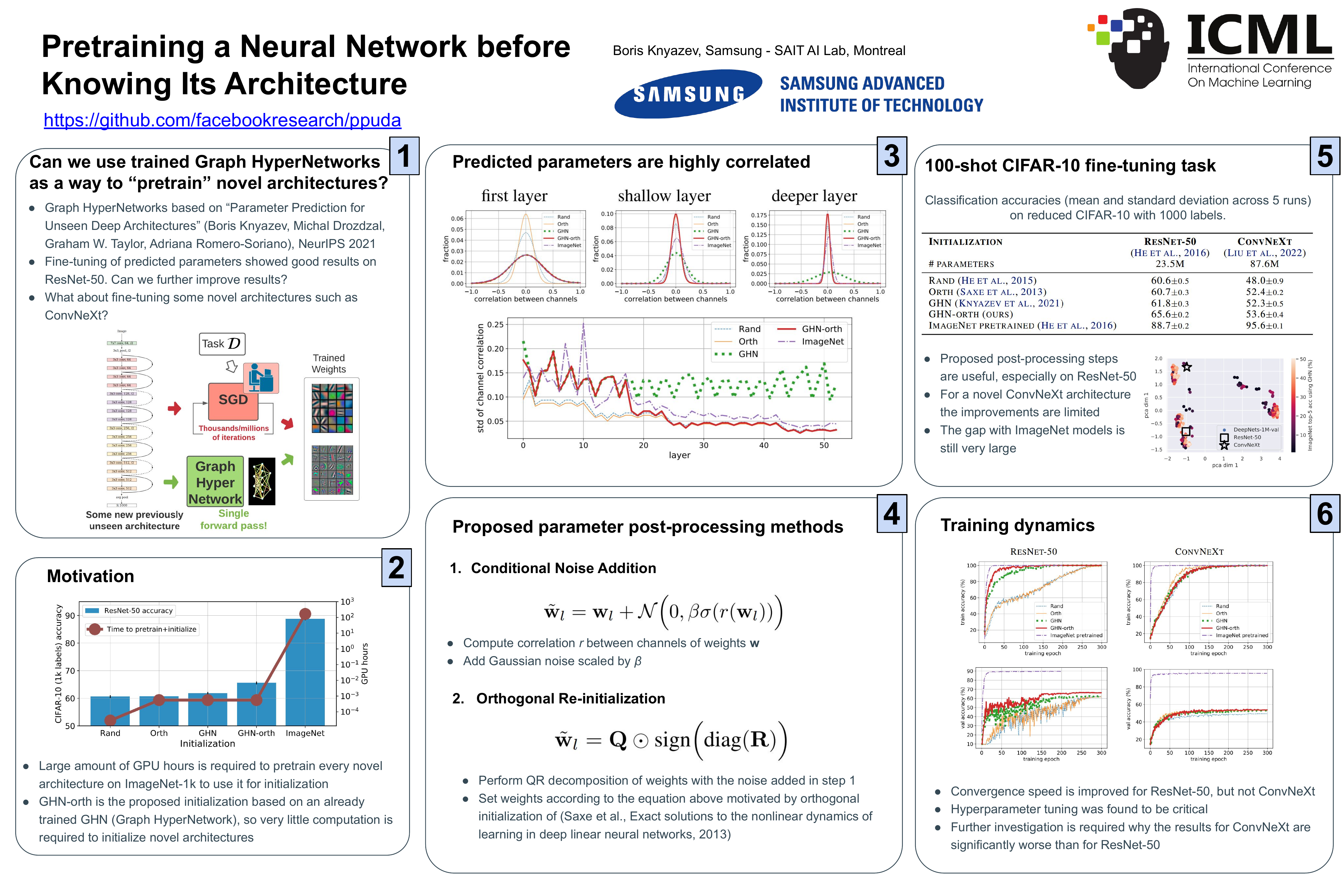
Training large neural networks is possible by training a smaller hypernetwork that predicts parameters for the large ones. A recently released Graph HyperNetwork (GHN) trained this way on one million of smaller ImageNet architectures is able to predict parameters for large unseen networks such as ResNet-50. While networks with predicted parameters lose performance on the source task, the predicted parameters have been found useful for fine-tuning on other tasks. We study if fine-tuning based on the same GHN is still useful on novel strong architectures that were published after the GHN had been trained. We found that for recent architectures such as ConvNeXt, GHN initialization becomes less useful than for ResNet-50. One potential reason is the increased distribution shift of novel architectures from those used to train the GHN. We also found that the predicted parameters lack the diversity necessary to successfully fine-tune parameters with gradient descent. We alleviate this limitation by applying simple post-processing techniques to predicted parameters before fine-tuning them on a target task and improve fine-tuning of ResNet-50 and ConvNeXt.