Recursive History Representations for Unsupervised Reinforcement Learning in Multiple-Environments
{kind=link}
Abstract
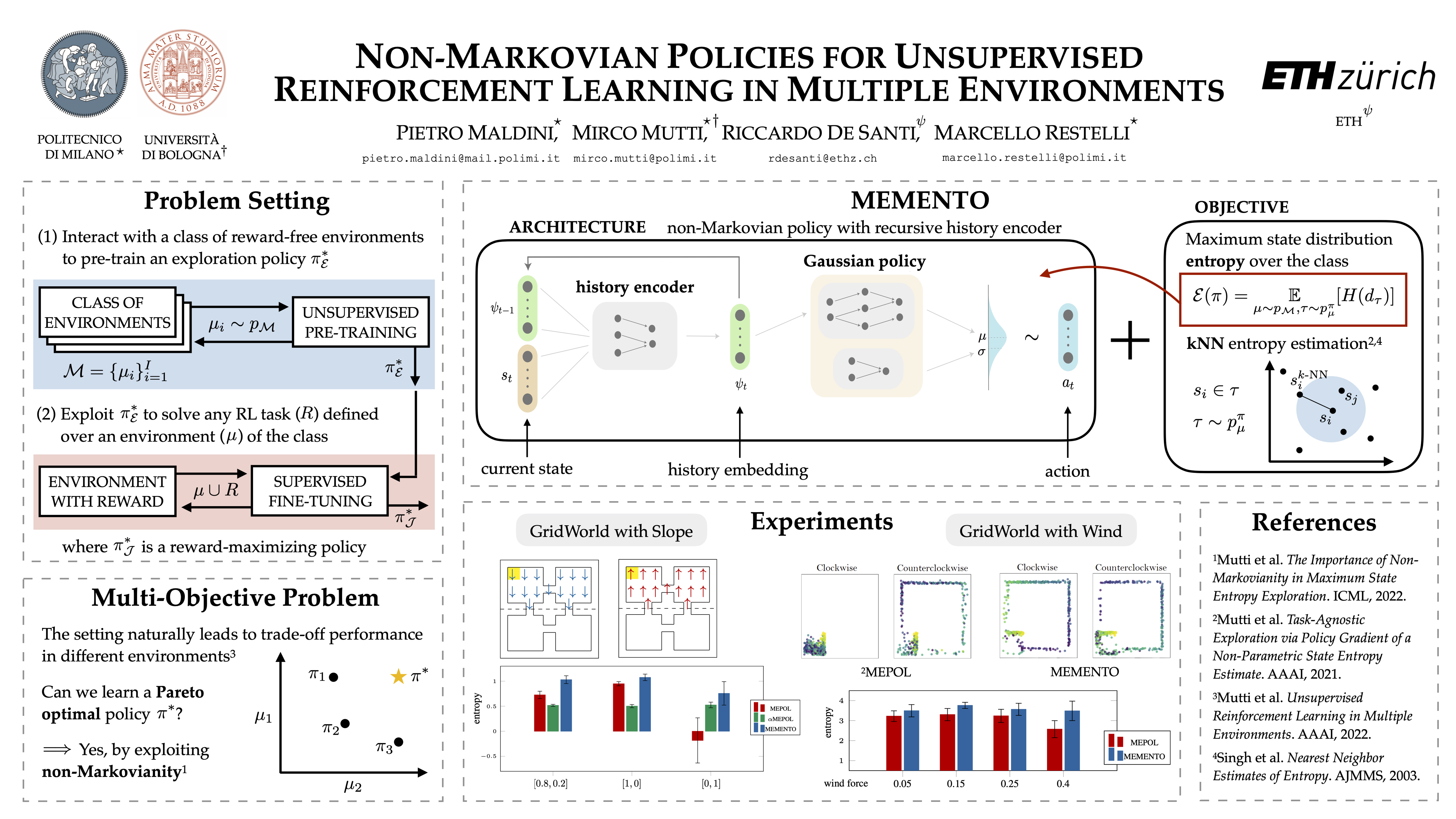
In recent years, the area of Unsupervised Reinforcement Learning (URL) has gained particular relevance. In this setting, an agent is pre-trained in an environment with reward-free interactions, often through a maximum state entropy objective that drives the agent towards a uniform coverage of the state space. It has been shown that this pre-training phase leads to significant performance improvements in downstream tasks later given to the agent to solve. The multiple-environments version of this setting introduces the problem of controlling the performance trade-offs in the environment class and leads to the following question: Can we build Pareto optimal policies for multiple-environments URL? In this work, we answer this question by proposing a novel non-Markovian policy architecture to be trained with the maximum state entropy objective. This architecture showcases significant empirical advantages when compared to state-of-the-art Markovian agents.