Towards Learning to Imitate from a Single Video Demonstration
{kind=link}
Abstract
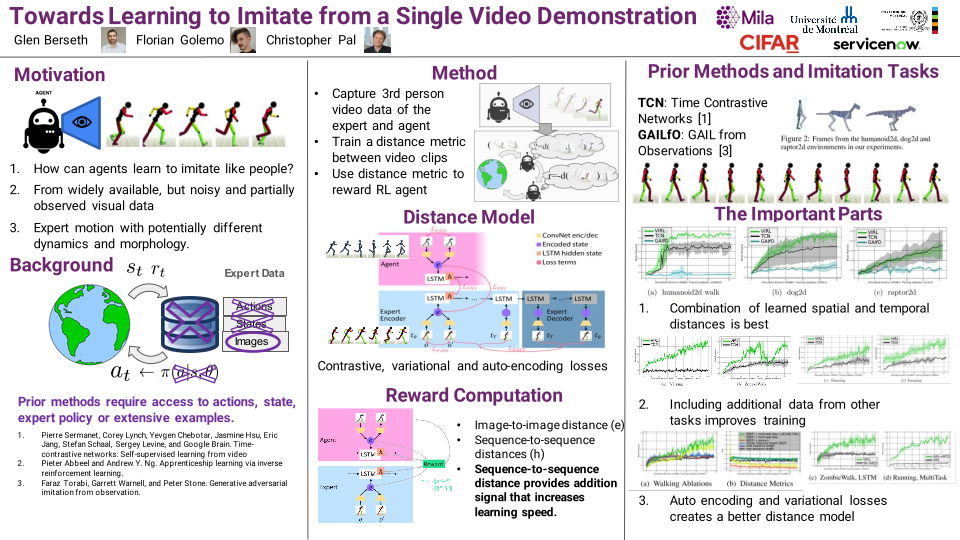
Agents that can learn to imitate behaviours observed in video -- without having direct access to internal state or action information of the observed agent -- are more suitable for learning in the natural world. However, formulating a reinforcement learning (RL) agent that facilitates this goal remains a significant challenge. We approach this challenge using contrastive training to learn a reward function by comparing an agent's behaviour with a single demonstration. We use a Siamese recurrent neural network architecture to learn rewards in space and time between motion clips while training an RL policy to minimize this distance. Through experimentation, we also find that the inclusion of multi-task data and additional image encoding losses improve the temporal consistency of the learned rewards and, as a result, significantly improve policy learning. We demonstrate our approach on simulated humanoid, dog, and raptor agents in 2D and quadruped and humanoid agents in 3D. We show that our method outperforms current state-of-the-art techniques and can learn to imitate behaviours from a single video demonstration.