Boosting Offline Reinforcement Learning with Action Preference Query
{kind=link}
Abstract
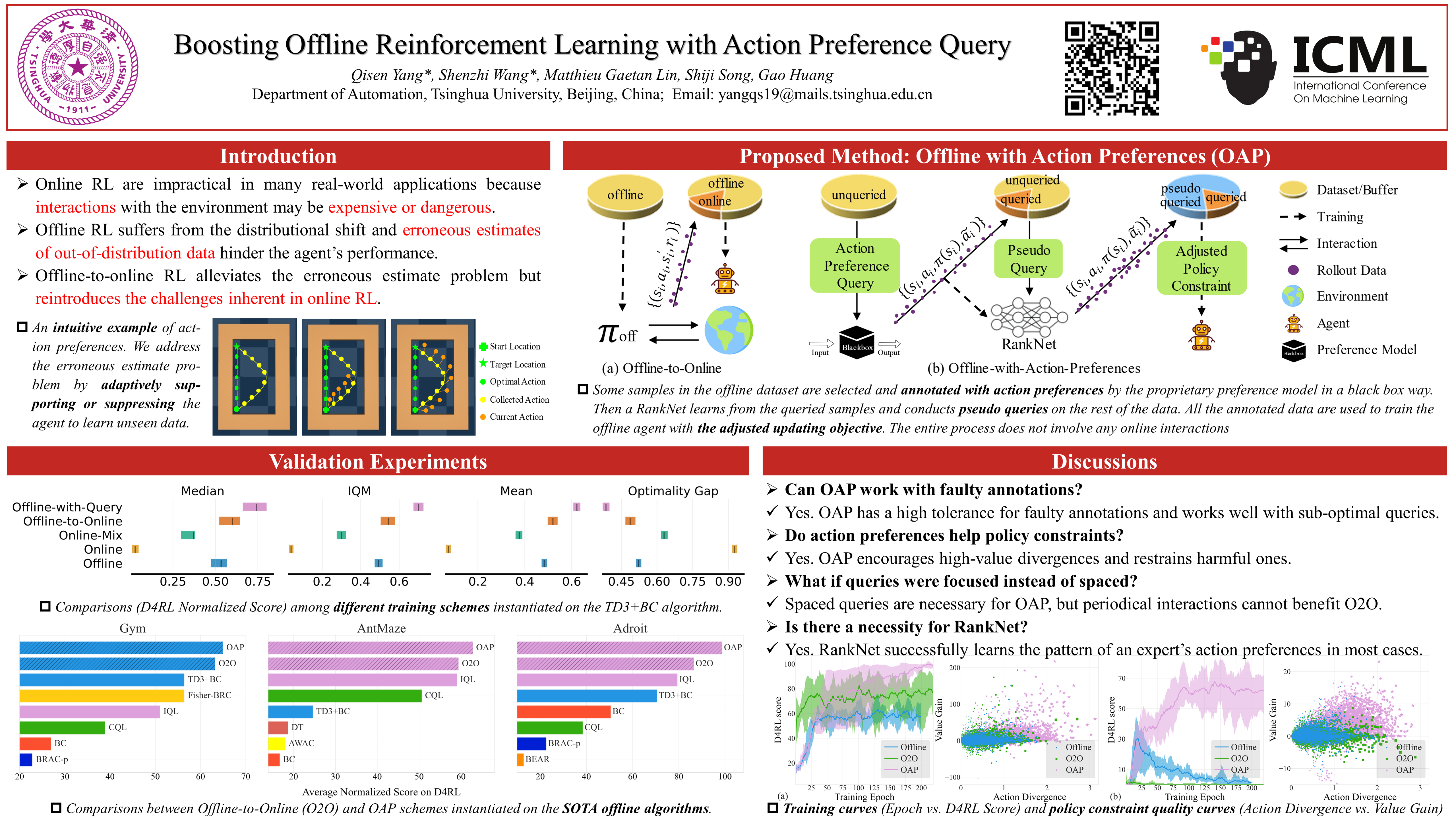
Training practical agents usually involve offline and online reinforcement learning (RL) to balance the policy's performance and interaction costs. In particular, online fine-tuning has become a commonly used method to correct the erroneous estimates of out-of-distribution data learned in the offline training phase. However, even limited online interactions can be inaccessible or catastrophic for high-stake scenarios like healthcare and autonomous driving. In this work, we introduce an interaction-free training scheme dubbed Offline-with-Action-Preferences (OAP). The main insight is that, compared to online fine-tuning, querying the preferences between pre-collected and learned actions can be equally or even more helpful to the erroneous estimate problem. By adaptively encouraging or suppressing policy constraint according to action preferences, OAP could distinguish overestimation from beneficial policy improvement and thus attains a more accurate evaluation of unseen data. Theoretically, we prove a lower bound of the behavior policy's performance improvement brought by OAP. Moreover, comprehensive experiments on the D4RL benchmark and state-of-the-art algorithms demonstrate that OAP yields higher (29% on average) scores, especially on challenging AntMaze tasks (98% higher).