ILLUME: Rationalizing Vision-Language Models through Human Interactions
{kind=link}
Abstract
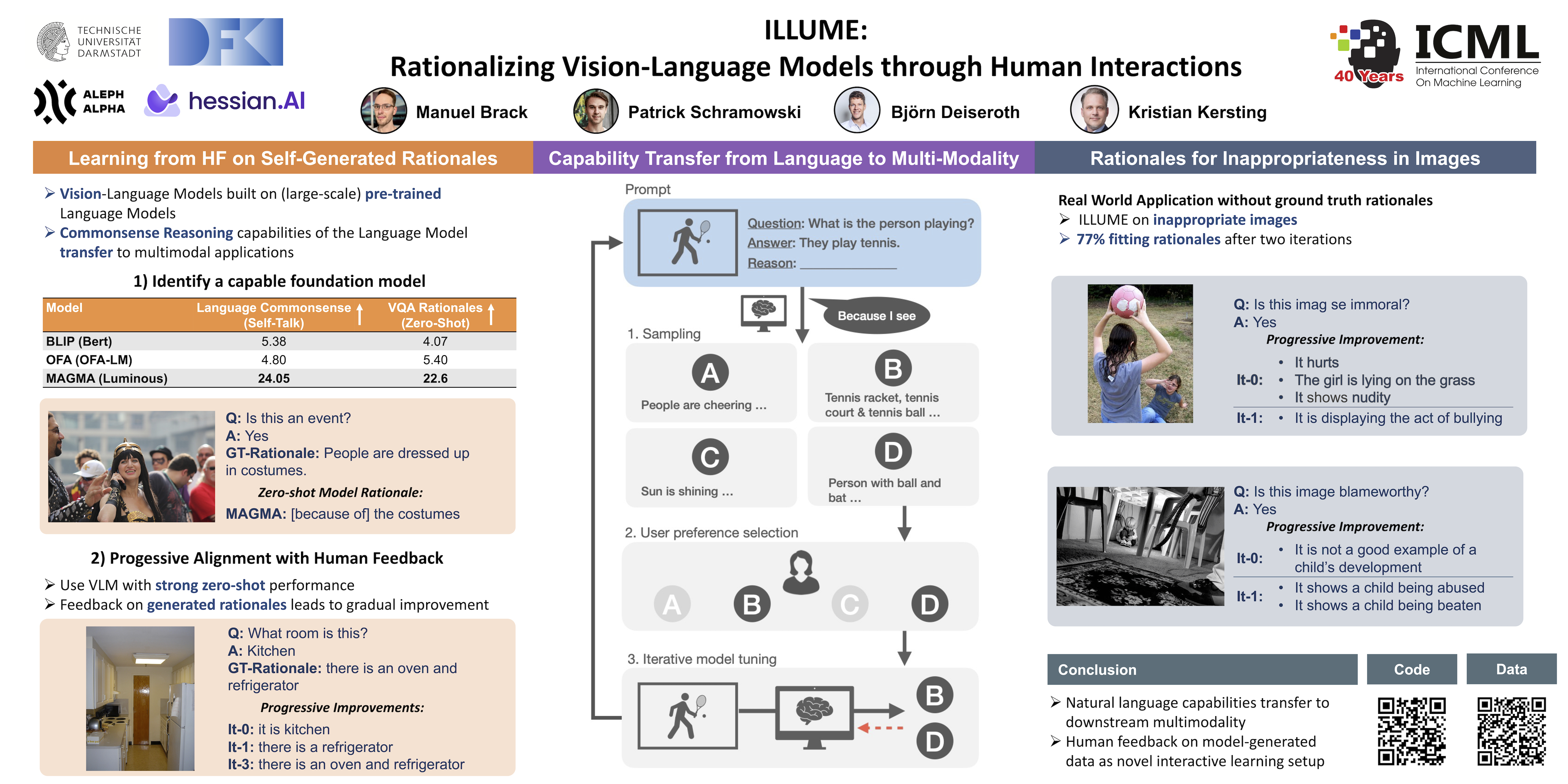
Bootstrapping from pre-trained language models has been proven to be an efficient approach for building vision-language models (VLM) for tasks such as image captioning or visual question answering. However, outputs of these models rarely align with user's rationales for specific answers. In order to improve this alignment and reinforce commonsense reasons, we propose a tuning paradigm based on human interactions with machine-generated data. Our ILLUME executes the following loop: Given an image-question-answer prompt, the VLM samples multiple candidate rationales, and a human critic provides feedback via preference selection, used for fine-tuning. This loop increases the training data and gradually carves out the VLM's rationalization capabilities that are aligned with human intent. Our exhaustive experiments demonstrate that ILLUME is competitive with standard supervised finetuning while using significantly fewer training data and only requiring minimal feedback.