Supported Trust Region Optimization for Offline Reinforcement Learning
{kind=link}
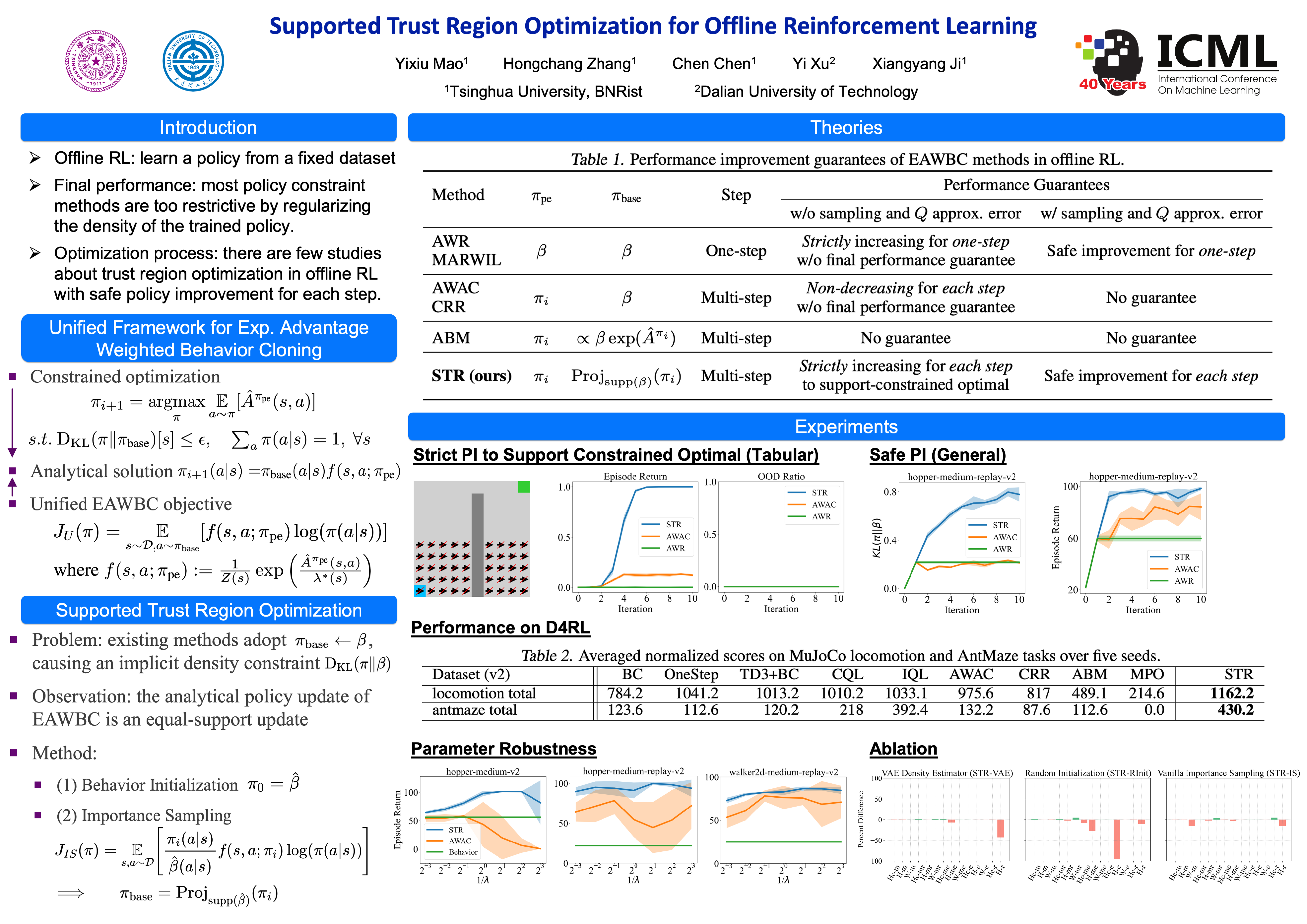
Abstract
Offline reinforcement learning suffers from the out-of-distribution issue and extrapolation error. Most policy constraint methods regularize the density of the trained policy towards the behavior policy, which is too restrictive in most cases. We propose Supported Trust Region optimization (STR) which performs trust region policy optimization with the policy constrained within the support of the behavior policy, enjoying the less restrictive support constraint. We show that, when assuming no approximation and sampling error, STR guarantees strict policy improvement until convergence to the optimal support-constrained policy in the dataset. Further with both errors incorporated, STR still guarantees safe policy improvement for each step. Empirical results validate the theory of STR and demonstrate its state-of-the-art performance on MuJoCo locomotion domains and much more challenging AntMaze domains.