On Distribution Dependent Sub-Logarithmic Query Time of Learned Indexing
Sepanta Zeighami ⋅ Cyrus Shahabi
2023 Poster
{kind=link}
Abstract
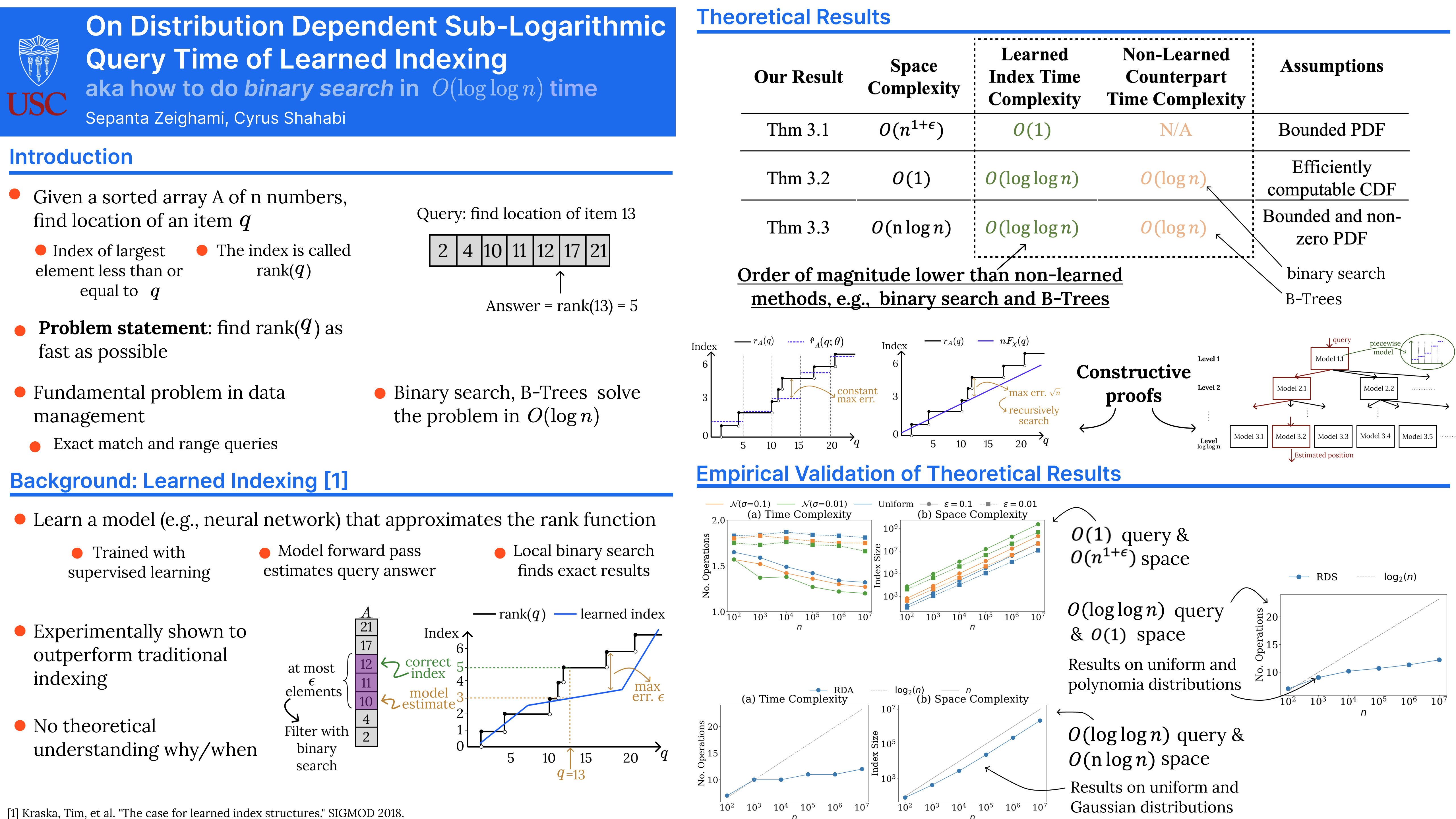
A fundamental problem in data management is to find the elements in an array that match a query. Recently, learned indexes are being extensively used to solve this problem, where they learn a model to predict the location of the items in the array. They are empirically shown to outperform non-learned methods (e.g., B-trees or binary search that answer queries in $O(\log n)$ time) by orders of magnitude. However, success of learned indexes has not been theoretically justified. Only existing attempt shows the same query time of $O(\log n)$, but with a constant factor improvement in space complexity over non-learned methods, under some assumptions on data distribution. In this paper, we significantly strengthen this result, showing that under mild assumptions on data distribution, and the same space complexity as non-learned methods, learned indexes can answer queries in $O(\log\log n)$ expected query time. We also show that allowing for slightly larger but still near-linear space overhead, a learned index can achieve $O(1)$ expected query time. Our results theoretically prove learned indexes are orders of magnitude faster than non-learned methods, theoretically grounding their empirical success.
Video
Chat is not available.
Successful Page Load