Discovering Object-Centric Generalized Value Functions From Pixels
{kind=link}
Abstract
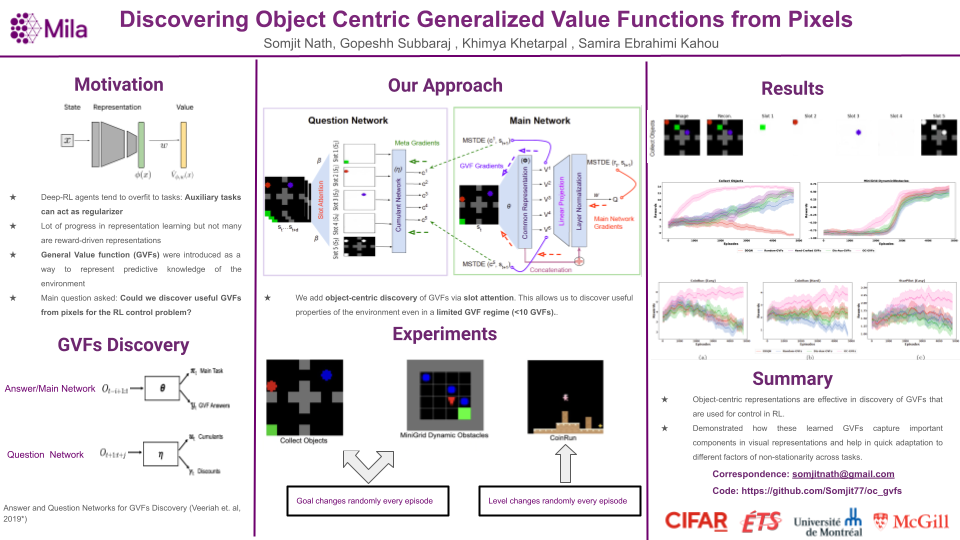
Deep Reinforcement Learning has shown significant progress in extracting useful representations from high-dimensional inputs albeit using hand-crafted auxiliary tasks and pseudo rewards. Automatically learning such representations in an object-centric manner geared towards control and fast adaptation remains an open research problem. In this paper, we introduce a method that tries to discover meaningful features from objects, translating them to temporally coherent `question' functions and leveraging the subsequent learned general value functions for control. We compare our approach with state-of-the-art techniques alongside other ablations and show competitive performance in both stationary and non-stationary settings. Finally, we also investigate the discovered general value functions and through qualitative analysis show that the learned representations are not only interpretable but also, centered around objects that are invariant to changes across tasks facilitating fast adaptation.