Effectively Using Public Data in Privacy Preserving Machine Learning
Milad Nasresfahani ⋅ Saeed Mahloujifar ⋅ Xinyu Tang ⋅ Prateek Mittal ⋅ Amir Houmansadr
2023 Poster
{kind=link}
Abstract
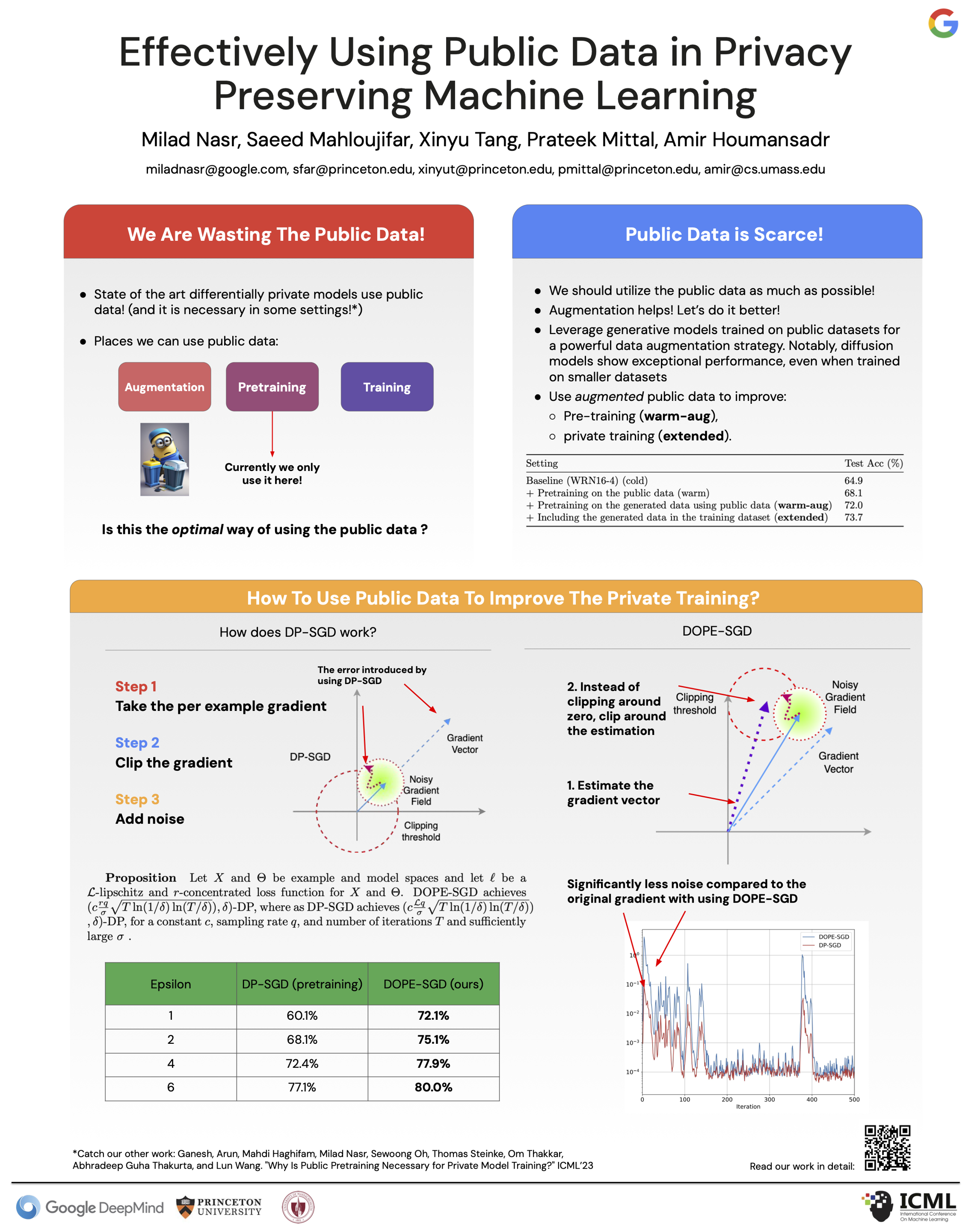
Differentially private (DP) machine learning techniques are notorious for their degradation of model utility (e.g., they degrade classification accuracy). A recent line of work has demonstrated that leveraging *public data* can improve the trade-off between privacy and utility when training models with DP guaranteed. In this work, we further explore the potential of using public data in DP models, showing that utility gains can in fact be significantly higher than what shown in prior works. Specifically, we introduce DOPE-SGD, a modified DP-SGD algorithm that leverages public data during its training. DOPE-SGD uses public data in two complementary ways: (1) it uses advance augmentation techniques that leverages public data to generate synthetic data that is effectively embedded in multiple steps of the training pipeline; (2) it uses a modified gradient clipping mechanism (which is a standard technique in DP training) to change the *origin* of gradient vectors using the information inferred from available public and synthetic data, therefore boosting utility. We also introduce a technique to ensemble intermediate DP models by leveraging the post processing property of differential privacy to further improve the accuracy of the predictions. Our experimental results demonstrate the effectiveness of our approach in improving the state-of-the-art in DP machine learning across multiple datasets, network architectures, and application domains. For instance, assuming access to $2,000$ public images, and for a privacy budget of $\varepsilon=2,\delta=10^{-5}$, our technique achieves an accuracy of $75.1\%$ on CIFAR10, significantly higher than $68.1\%$ achieved by the state of the art.
Video
Chat is not available.
Successful Page Load