Emergent Agentic Transformer from Chain of Hindsight Experience
{kind=link}
Abstract
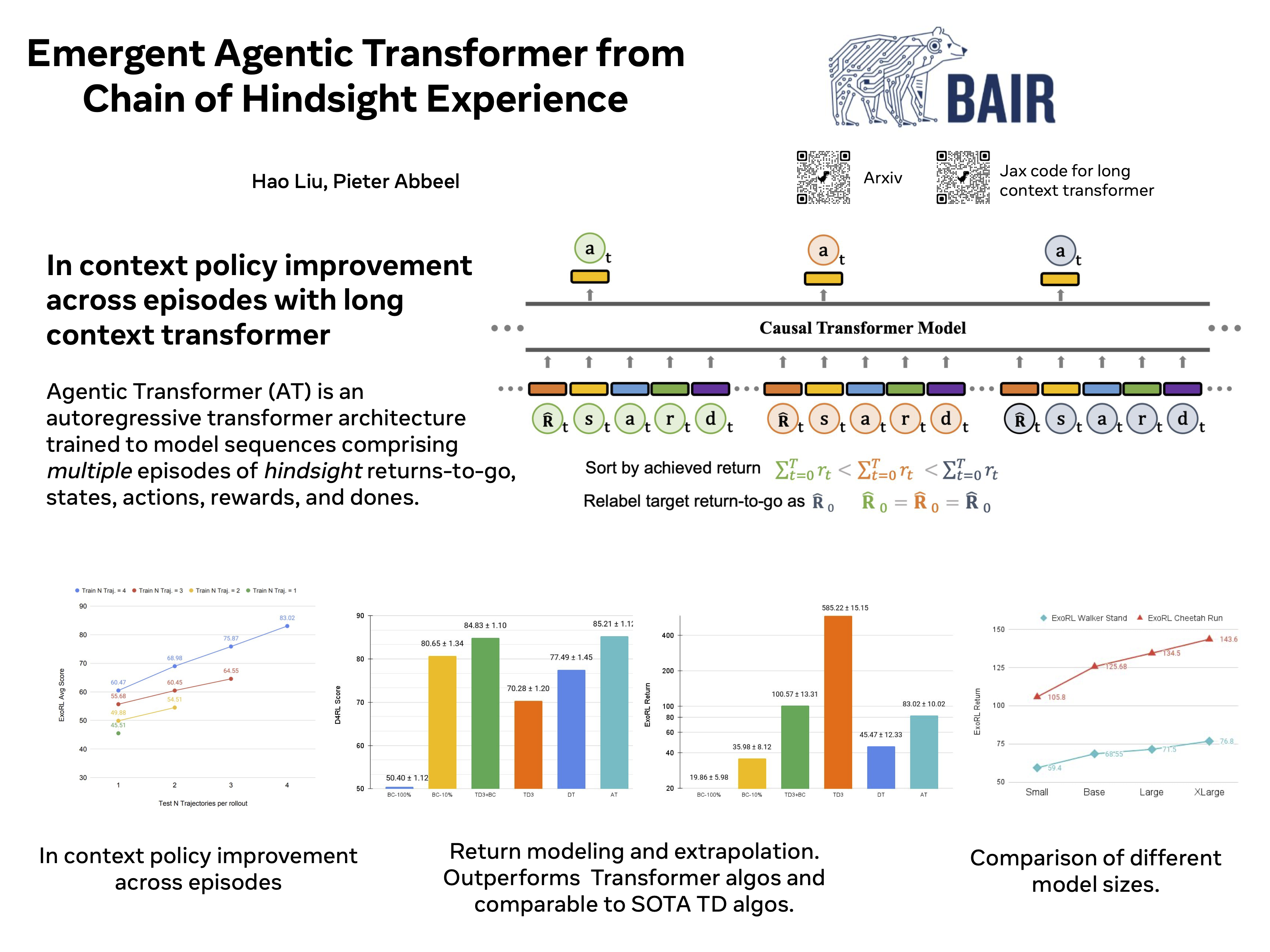
Large transformer models powered by diverse data and model scale have dominated natural language modeling and computer vision and pushed the frontier of multiple AI areas. In reinforcement learning (RL), despite many efforts into transformer-based policies, a key limitation, however, is that current transformer-based policies cannot learn by directly combining information from multiple sub-optimal trials. In this work, we address this issue using recently proposed chain of hindsight to relabel experience, where we train a transformer on a sequence of trajectory experience ascending sorted according to their total rewards. Our method consists of relabelling target return of each trajectory to the maximum total reward among in sequence of trajectories and training an autoregressive model to predict actions conditioning on past states, actions, rewards, target returns, and task completion tokens, the resulting model, Agentic Transformer (AT), can learn to improve upon itself both at training and test time. As we show on D4RL and ExoRL benchmarks, to the best our knowledge, this is the first time that a simple transformer-based model performs competitively with both temporal-difference and imitation-learning-based approaches, even from sub-optimal data. Our Agentic Transformer also shows a promising scaling trend that bigger models consistently improve results.