Understanding Gradient Regularization in Deep Learning: Efficient Finite-Difference Computation and Implicit Bias
{kind=link}
Abstract
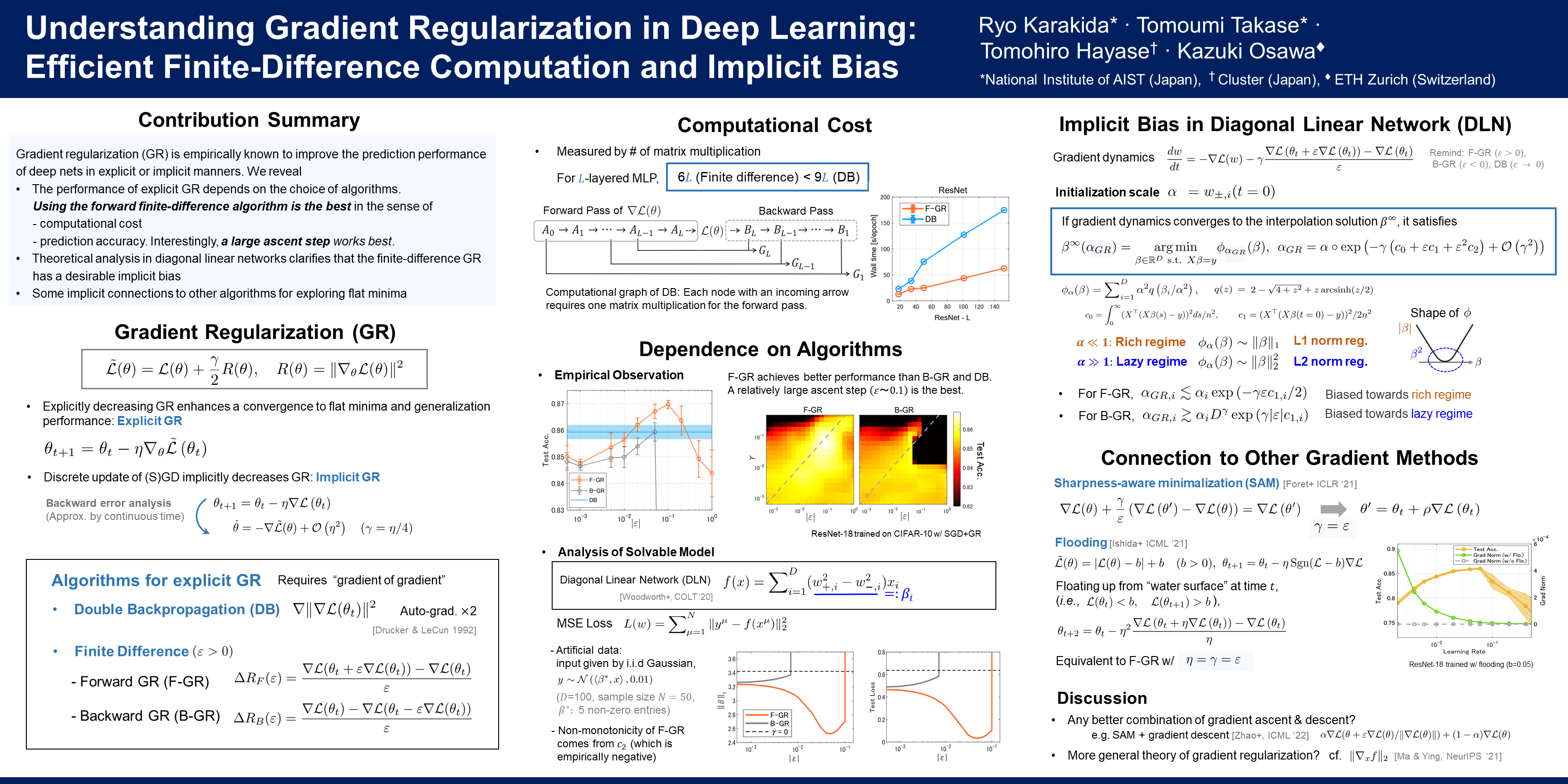
Gradient regularization (GR) is a method that penalizes the gradient norm of the training loss during training. While some studies have reported that GR can improve generalization performance, little attention has been paid to it from the algorithmic perspective, that is, the algorithms of GR that efficiently improve the performance. In this study, we first reveal that a specific finite-difference computation, composed of both gradient ascent and descent steps, reduces the computational cost of GR. Next, we show that the finite-difference computation also works better in the sense of generalization performance. We theoretically analyze a solvable model, a diagonal linear network, and clarify that GR has a desirable implicit bias to so-called rich regime and finite-difference computation strengthens this bias. Furthermore, finite-difference GR is closely related to some other algorithms based on iterative ascent and descent steps for exploring flat minima. In particular, we reveal that the flooding method can perform finite-difference GR in an implicit way. Thus, this work broadens our understanding of GR for both practice and theory.