Certified Robust Neural Networks: Generalization and Corruption Resistance
{kind=link}
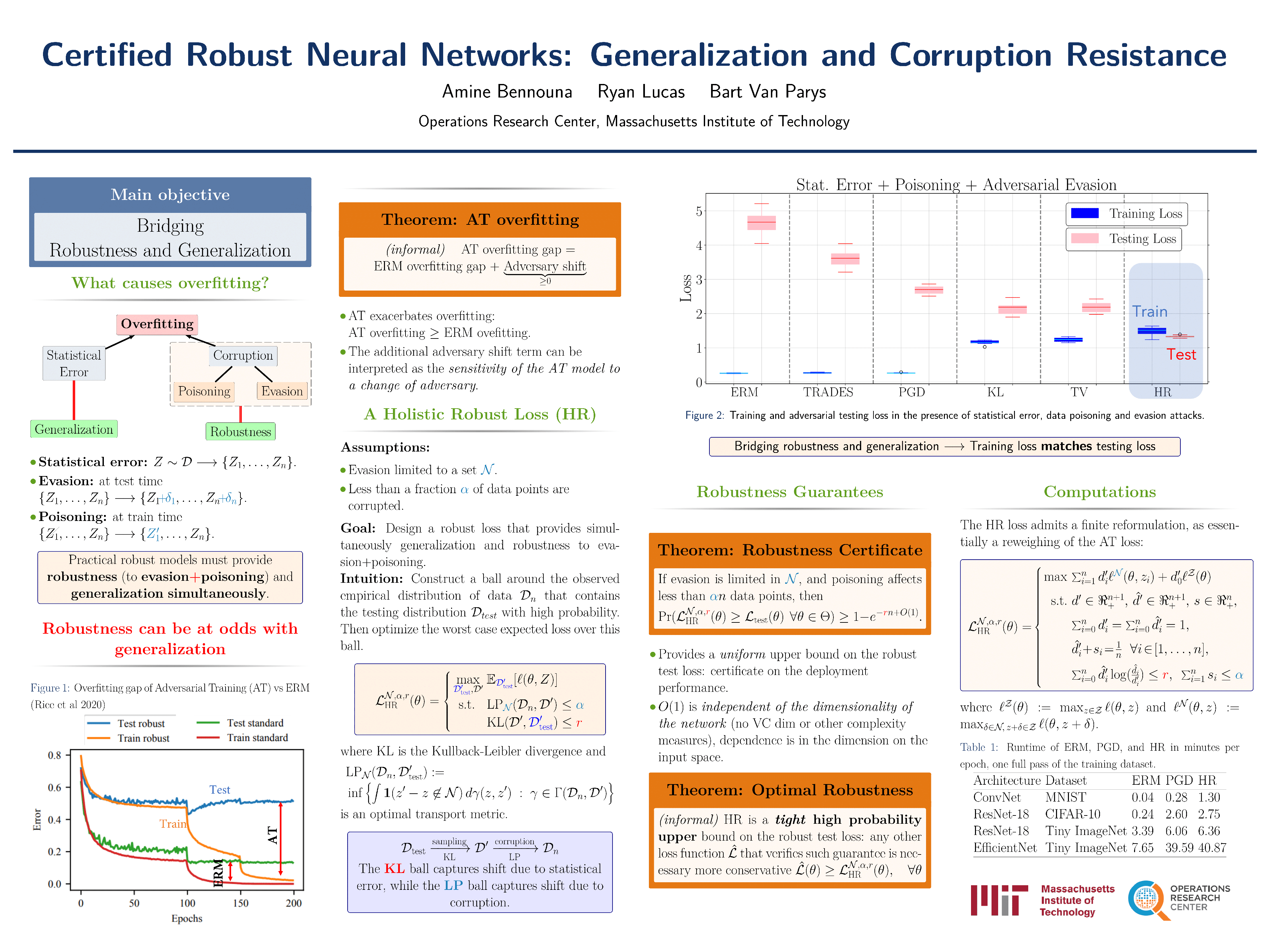
Abstract
Recent work have demonstrated that robustness (to "corruption") can be at odds with generalization. Adversarial training, for instance, aims to reduce the problematic susceptibility of modern neural networks to small data perturbations. Surprisingly, overfitting is a major concern in adversarial training despite being mostly absent in standard training. We provide here theoretical evidence for this peculiar ``robust overfitting'' phenomenon. Subsequently, we advance a novel distributionally robust loss function bridging robustness and generalization. We demonstrate both theoretically as well as empirically the loss to enjoy a certified level of robustness against two common types of corruption|data evasion and poisoning attacks|while ensuring guaranteed generalization. We show through careful numerical experiments that our resulting holistic robust (HR) training procedure yields SOTA performance. Finally, we indicate that HR training can be interpreted as a direct extension of adversarial training and comes with a negligible additional computational burden. A ready-to-use python library implementing our algorithm is available at https://github.com/RyanLucas3/HRNeuralNetworks.