The Regret of Exploration and the Control of Bad Episodes in Reinforcement Learning
Victor Boone ⋅ Bruno Gaujal
2023 Poster
{kind=link}
Abstract
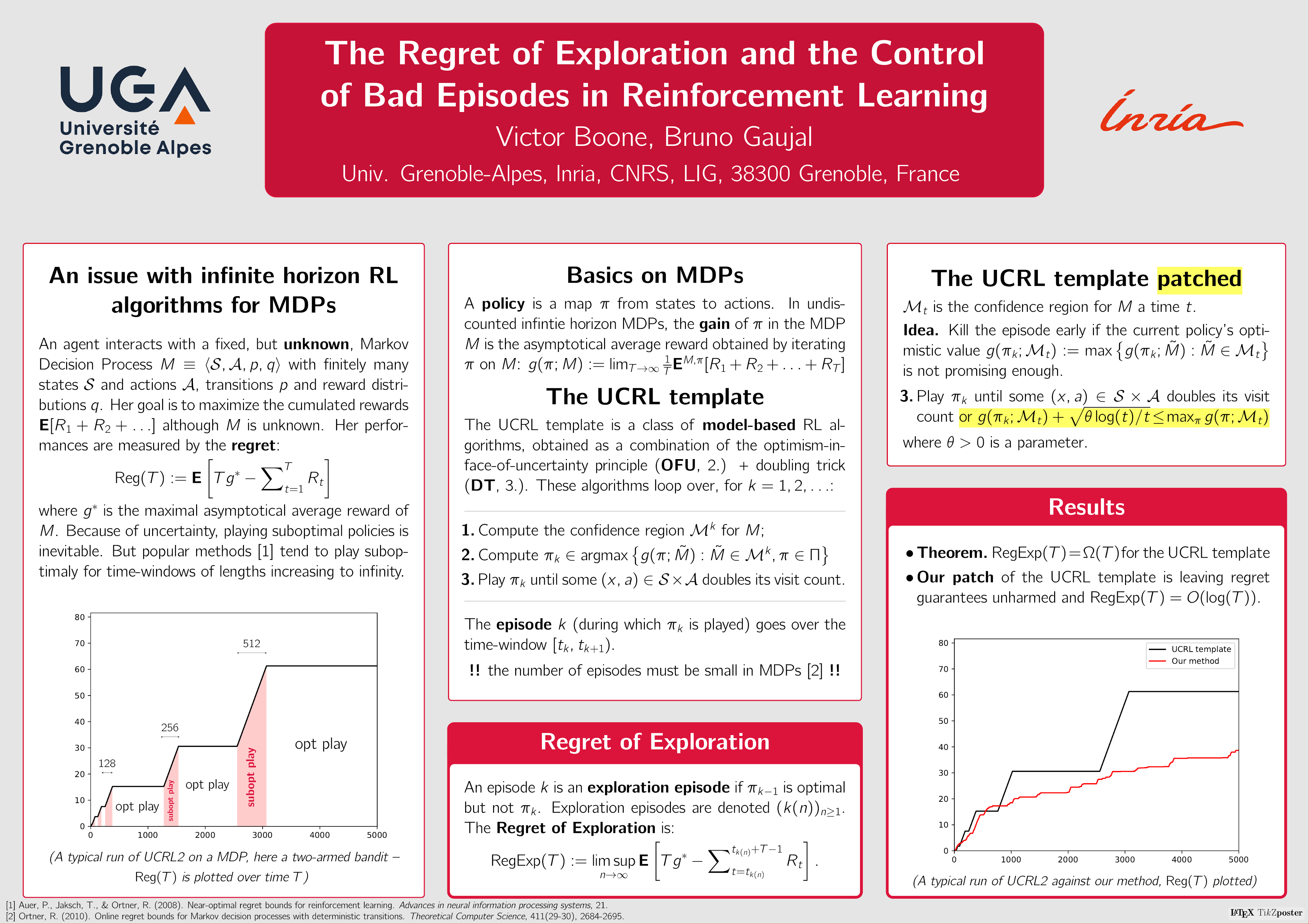
The first contribution of this paper is the introduction of a new performance measure of a RL algorithm that is more discriminating than the regret, that we call the *regret of exploration* that measures the asymptotic cost of exploration. The second contribution is a new *performance test* (PT) to end episodes in RL optimistic algorithms. This test is based on the performance of the current policy with respect to the best policy over the current confidence set. This is in contrast with all existing RL algorithms whose episode lengths are only based on the number of visits to the states. This modification does not harm the regret and brings an additional property. We show that while all current episodic RL algorithms have a linear regret of exploration, our method has a $O(\log{T})$ regret of exploration for non-degenerate deterministic MDPs.
Video
Chat is not available.
Successful Page Load