Computational Asymmetries in Robust Classification
Samuele Marro ⋅ Michele Lombardi
2023 Poster
{kind=link}
Abstract
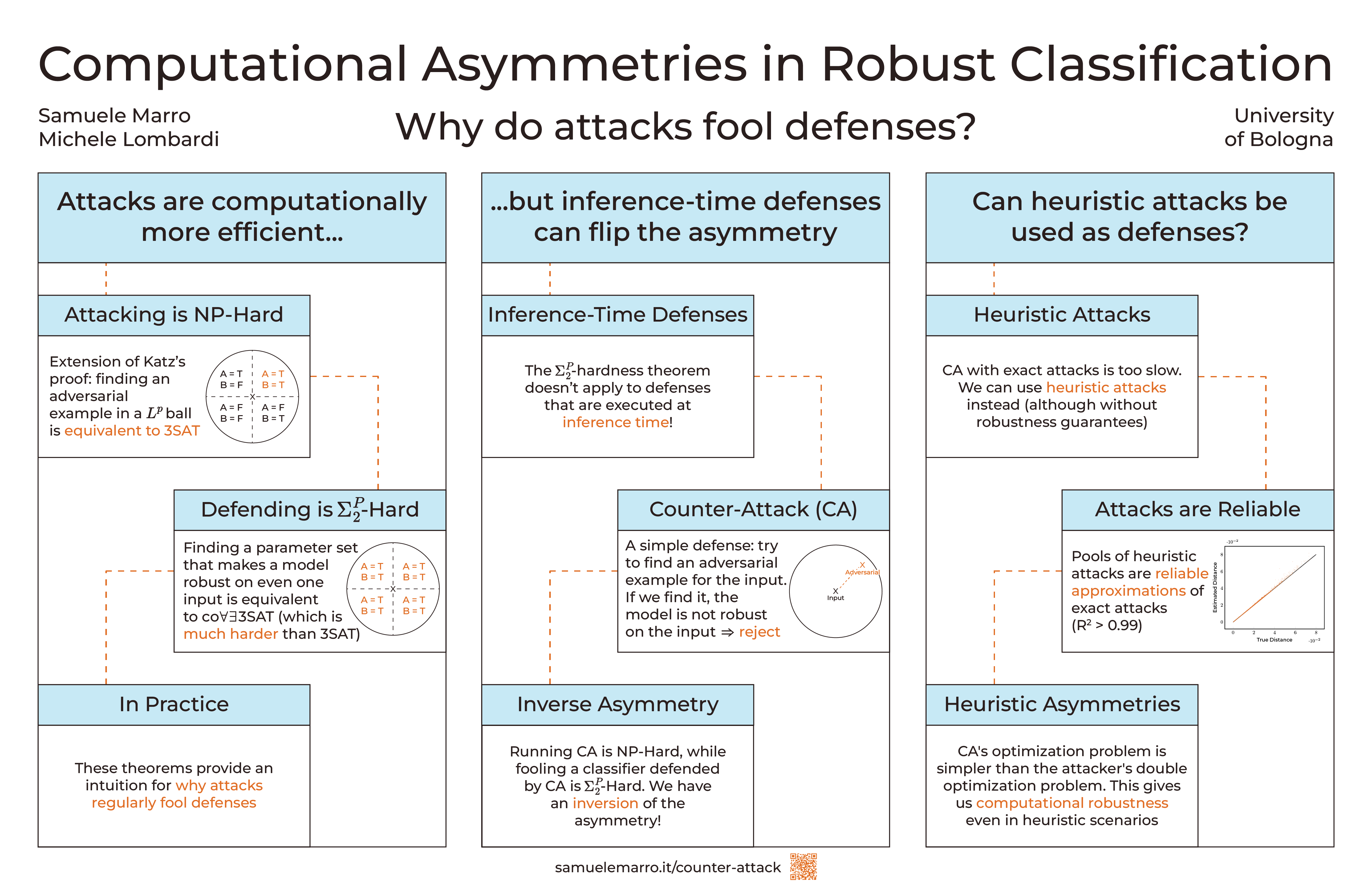
In the context of adversarial robustness, we make three strongly related contributions. First, we prove that while attacking ReLU classifiers is $\mathit{NP}$-hard, ensuring their robustness at training time is $\Sigma^2_P$-hard (even on a single example). This asymmetry provides a rationale for the fact that robust classifications approaches are frequently fooled in the literature. Second, we show that inference-time robustness certificates are not affected by this asymmetry, by introducing a proof-of-concept approach named Counter-Attack (CA). Indeed, CA displays a reversed asymmetry: running the defense is $\mathit{NP}$-hard, while attacking it is $\Sigma_2^P$-hard. Finally, motivated by our previous result, we argue that adversarial attacks can be used in the context of robustness certification, and provide an empirical evaluation of their effectiveness. As a byproduct of this process, we also release UG100, a benchmark dataset for adversarial attacks.
Video
Chat is not available.
Successful Page Load