When does Privileged information Explain Away Label Noise?
{kind=link}
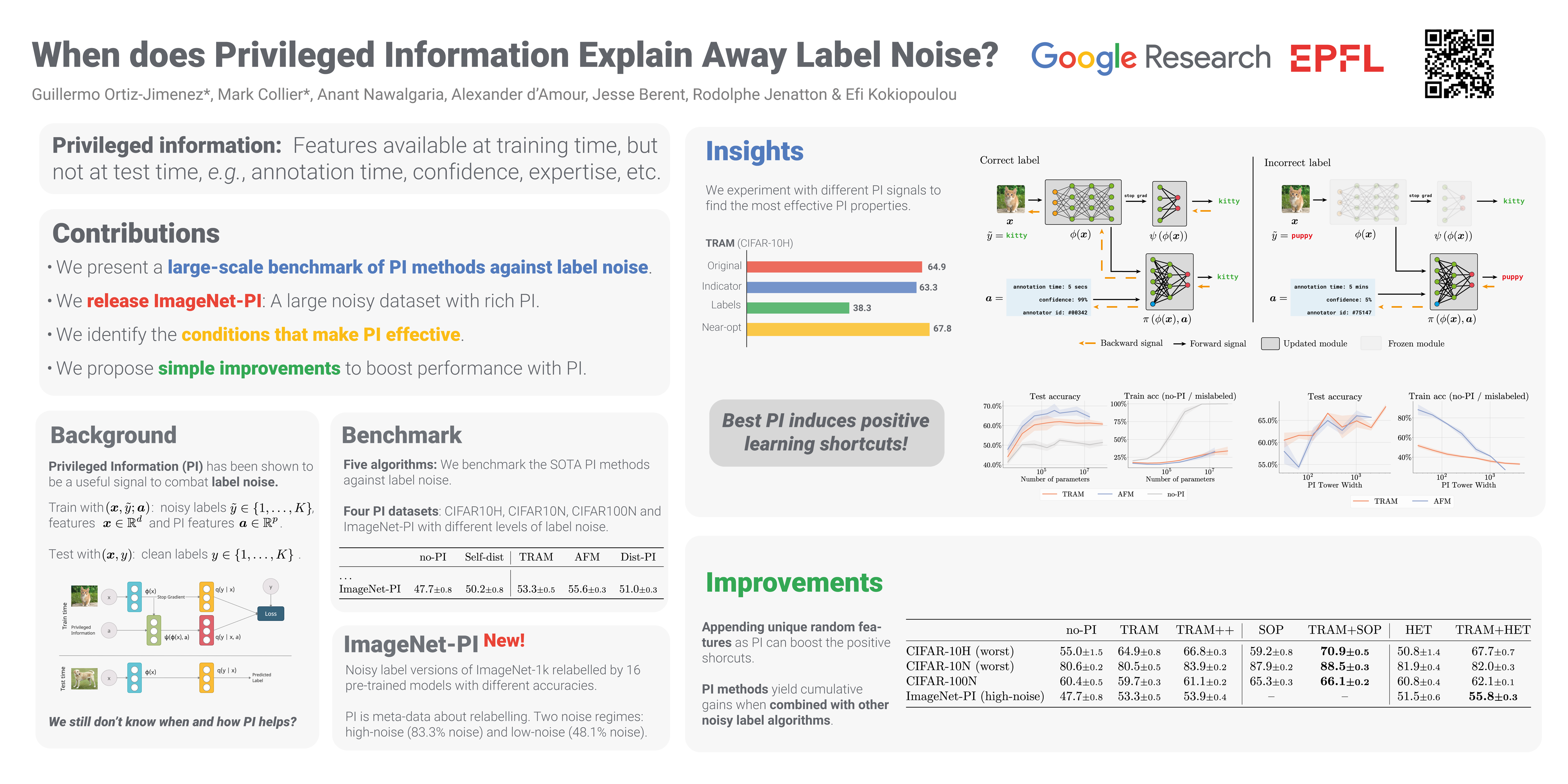
Abstract
Leveraging privileged information (PI), or features available during training but not at test time, has recently been shown to be an effective method for addressing label noise. However, the reasons for its effectiveness are not well understood. In this study, we investigate the role played by different properties of the PI in explaining away label noise. Through experiments on multiple datasets with real PI (CIFAR-N/H) and a new large-scale benchmark ImageNet-PI, we find that PI is most helpful when it allows networks to easily distinguish clean from noisy data, while enabling a learning shortcut to memorize the noisy examples. Interestingly, when PI becomes too predictive of the target label, PI methods often perform worse than their no-PI baselines. Based on these findings, we propose several enhancements to the state-of-the-art PI methods and demonstrate the potential of PI as a means of tackling label noise. Finally, we show how we can easily combine the resulting PI approaches with existing no-PI techniques designed to deal with label noise.