Efficient Exploration via Epistemic-Risk-Seeking Policy Optimization
{kind=link}
Abstract
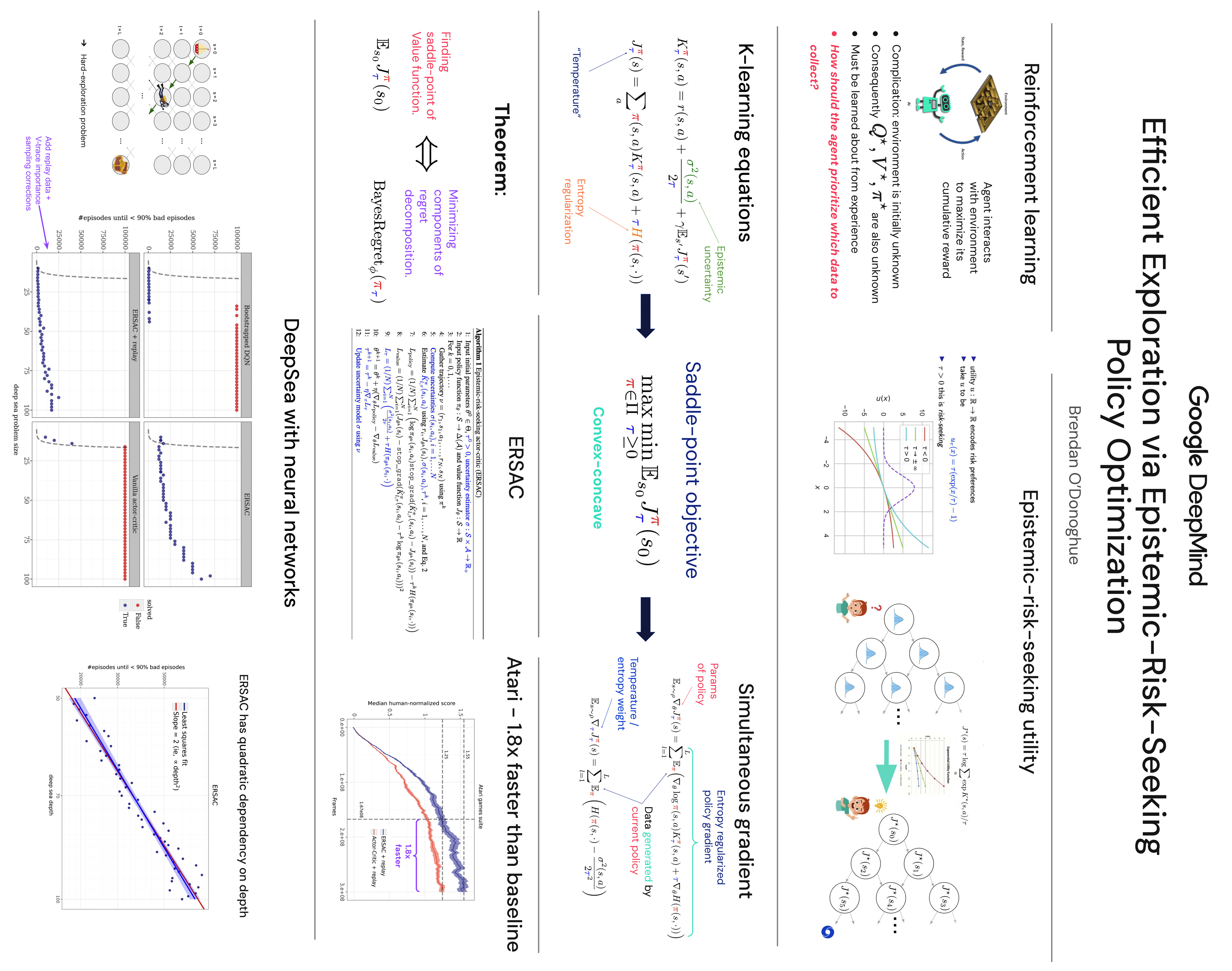
Exploration remains a key challenge in deep reinforcement learning (RL). Optimism in the face of uncertainty is a well-known heuristic with theoretical guarantees in the tabular setting, but how best to translate the principle to deep reinforcement learning, which involves online stochastic gradients and deep network function approximators, is not fully understood. In this paper we propose a new, differentiable optimistic objective that when optimized yields a policy that provably explores efficiently, with guarantees even under function approximation. Our new objective is a zero-sum two-player game derived from endowing the agent with an epistemic-risk-seeking utility function, which converts uncertainty into value and encourages the agent to explore uncertain states. We show that the solution to this game minimizes an upper bound on the regret, with the 'players' each attempting to minimize one component of a particular regret decomposition. We derive a new model-free algorithm which we call 'epistemic-risk-seeking actor-critic' (ERSAC), which is simply an application of simultaneous stochastic gradient ascent-descent to the game. Finally, we discuss a recipe for incorporating off-policy data and show that combining the risk-seeking objective with replay data yields a double benefit in terms of statistical efficiency. We conclude with some results showing good performance of a deep RL agent using the technique on the challenging 'DeepSea' environment, showing significant performance improvements even over other efficient exploration techniques, as well as improved performance on the Atari benchmark.