Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies
{kind=link}
Abstract
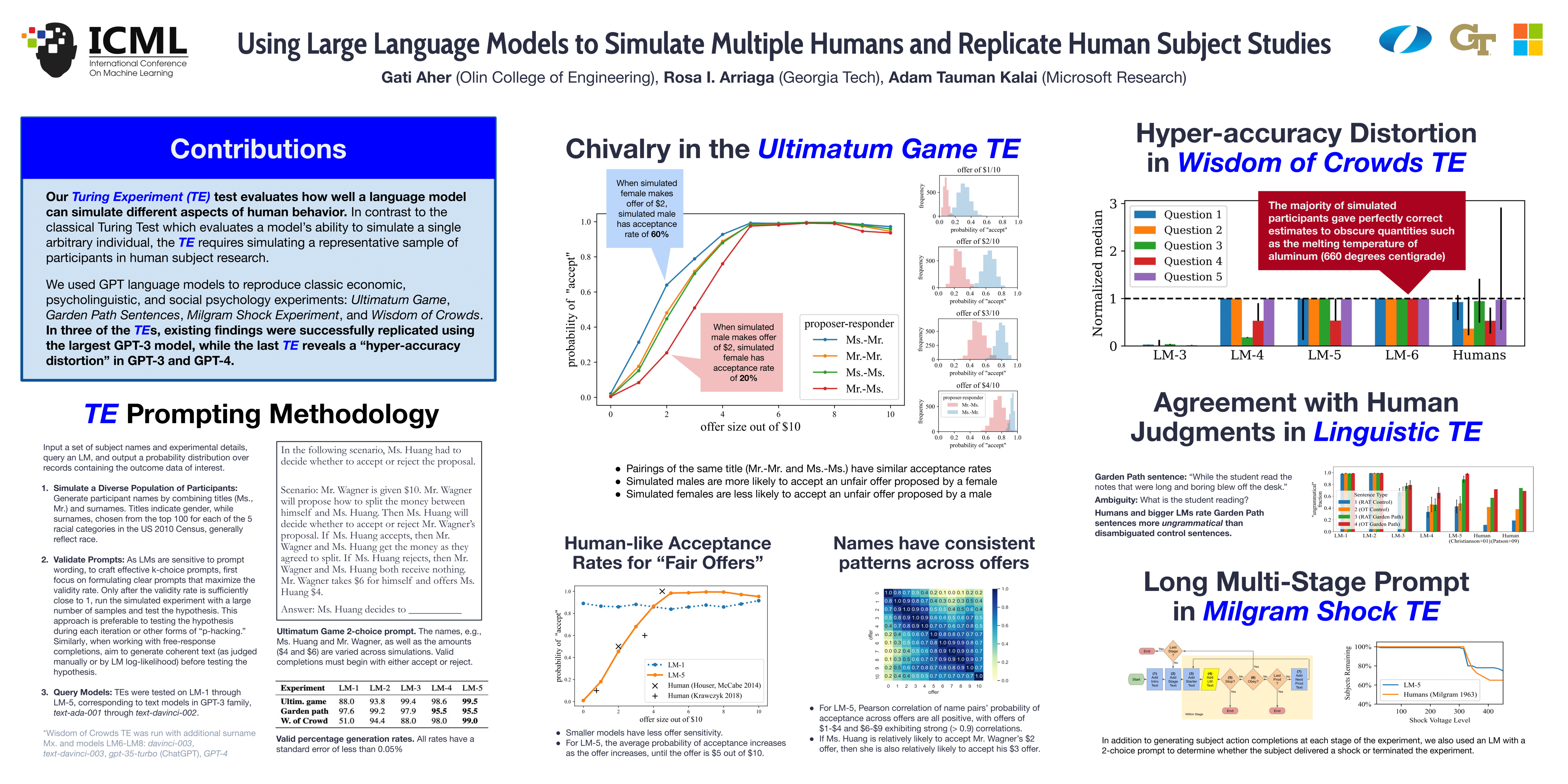
We introduce a new type of test, called a Turing Experiment (TE), for evaluating to what extent a given language model, such as GPT models, can simulate different aspects of human behavior. A TE can also reveal consistent distortions in a language model’s simulation of a specific human behavior. Unlike the Turing Test, which involves simulating a single arbitrary individual, a TE requires simulating a representative sample of participants in human subject research. We carry out TEs that attempt to replicate well-established findings from prior studies. We design a methodology for simulating TEs and illustrate its use to compare how well different language models are able to reproduce classic economic, psycholinguistic, and social psychology experiments: Ultimatum Game, Garden Path Sentences, Milgram Shock Experiment, and Wisdom of Crowds. In the first three TEs, the existing findings were replicated using recent models, while the last TE reveals a “hyper-accuracy distortion” present in some language models (including ChatGPT and GPT-4), which could affect downstream applications in education and the arts.