Model-based Reinforcement Learning with Scalable Composite Policy Gradient Estimators
{kind=link}
Abstract
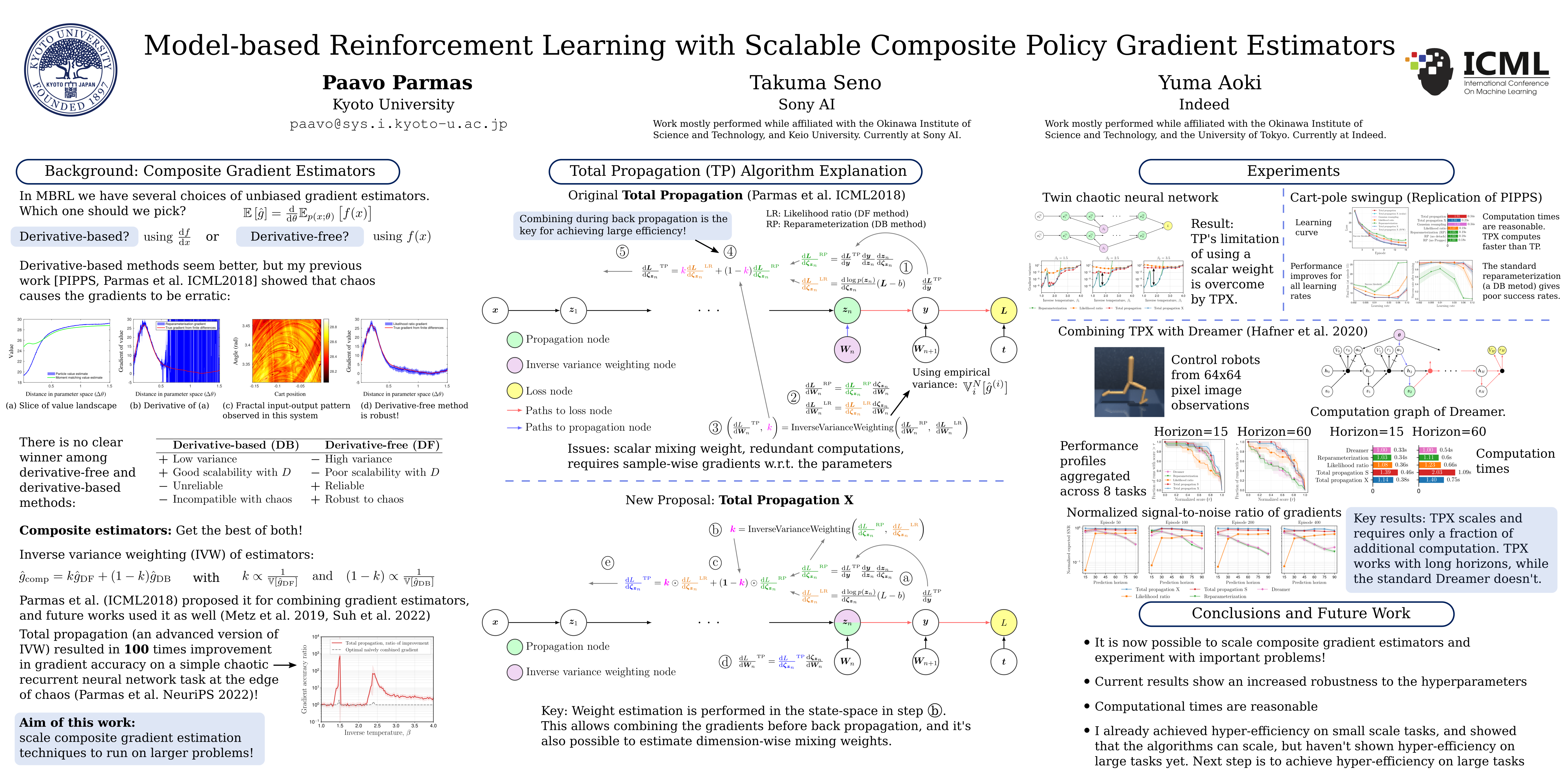
In model-based reinforcement learning (MBRL), policy gradients can be estimated either by derivative-free RL methods, such as likelihood ratio gradients (LR), or by backpropagating through a differentiable model via reparameterization gradients (RP). Instead of using one or the other, the Total Propagation (TP) algorithm in prior work showed that a combination of LR and RP estimators averaged using inverse variance weighting (IVW) can achieve orders of magnitude improvement over either method. However, IVW-based composite estimators have not yet been applied in modern RL tasks, as it is unclear if they can be implemented scalably. We propose a scalable method, Total Propagation X (TPX) that improves over TP by changing the node used for IVW, and employing coordinate wise weighting. We demonstrate the scalability of TPX by applying it to the state of the art visual MBRL algorithm Dreamer. The experiments showed that Dreamer fails with long simulation horizons, while our TPX works reliably for only a fraction of additional computation. One key advantage of TPX is its ease of implementation, which will enable experimenting with IVW on many tasks beyond MBRL.