Learned Thresholds Token Merging and Pruning for Vision Transformers
{kind=link}
Abstract
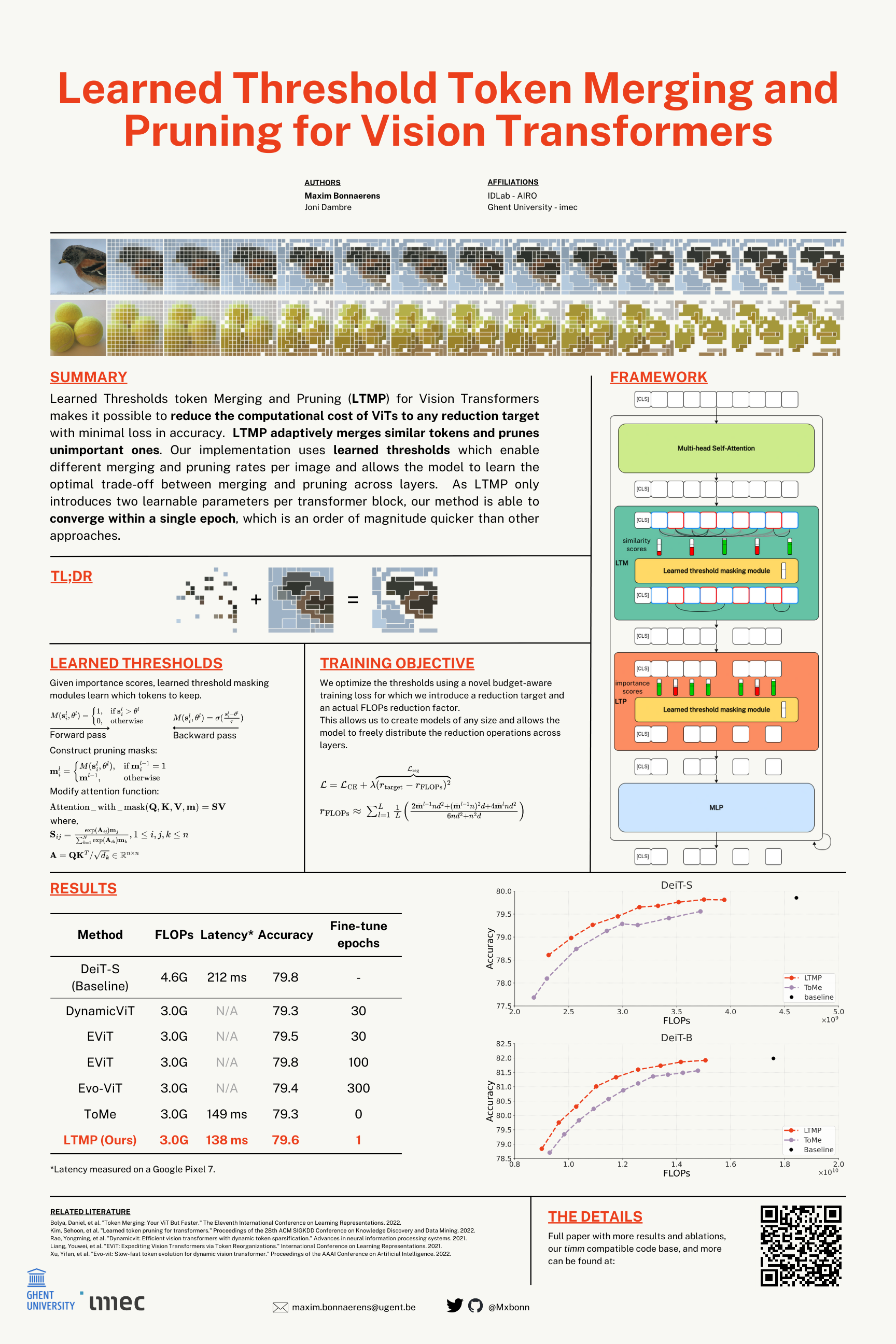
Vision transformers have demonstrated remarkable success in a wide range of computer vision tasks over the last years, however, their high computational costs remains a significant barrier to their practical deployment.In particular, the complexity of transformer models is quadratic with respect to the number of input tokens. Therefore techniques that reduce the number of input tokens that need to be processed have been proposed. This paper introduces Learned Thresholds token Merging and Pruning (LTMP), a novel approach that leverages the strengths of both token merging and token pruning.LTMP uses learned threshold masking modules that dynamically determine which tokens to merge and which to prune.Our results demonstrate that LTMP achieves state-of-the-art accuracy on ImageNet across various reduction rates while requiring only a single fine-tuning epoch, which is an order of magnitude faster than previous methods.