MOLE: MOdular Learning FramEwork via Mutual Information Maximization
Tianchao Li ⋅ Yulong Pei
{kind=link}
Abstract
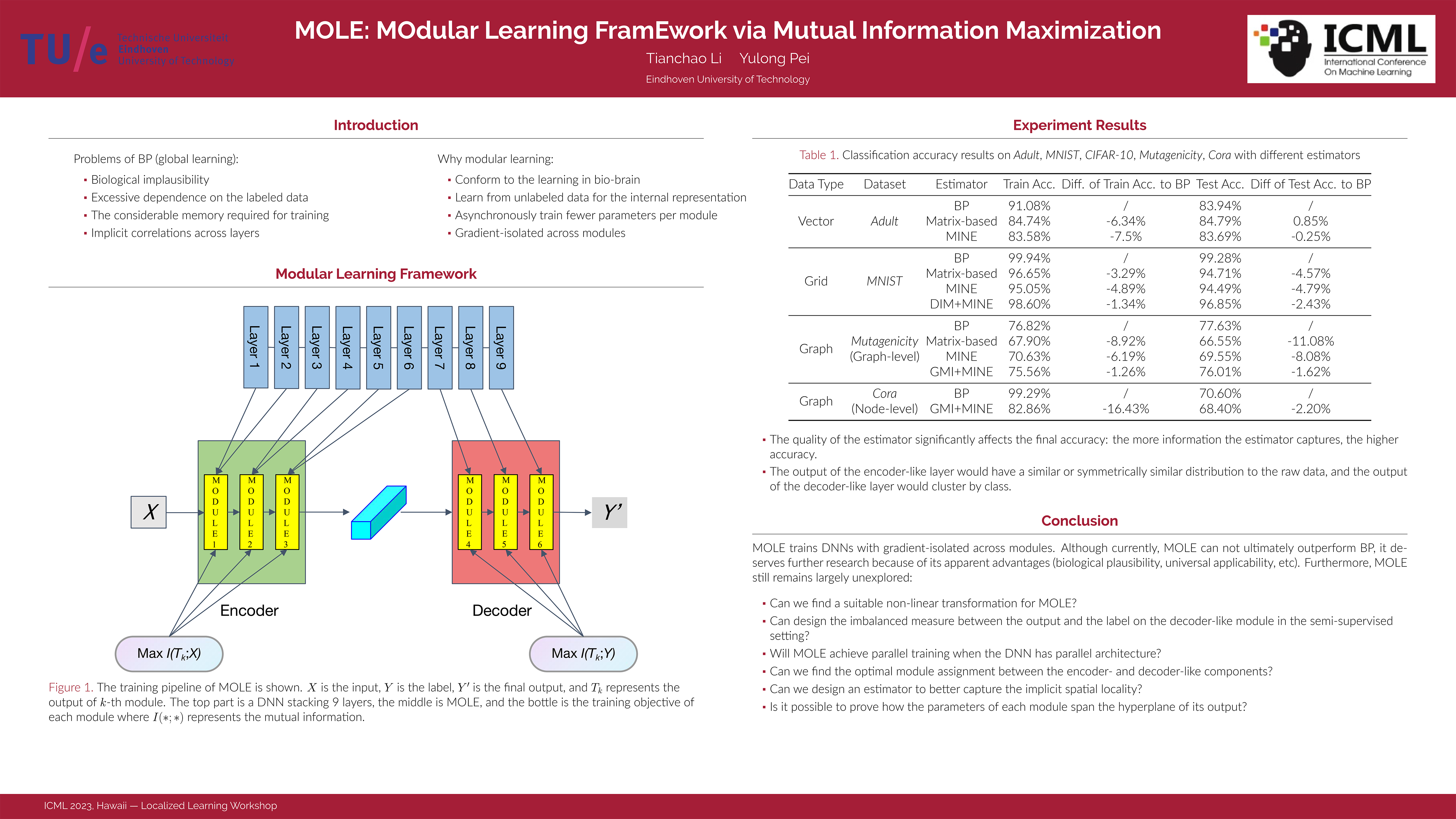
This paper is to introduce an asynchronous and local learning framework for neural networks, named Modular Learning Framework (MOLE). This framework modularizes neural networks by layers, defines the training objective via mutual information for each module, and sequentially trains each module by mutual information maximization. MOLE makes the training become local optimization with gradient-isolated across modules, and this scheme is more biologically plausible than BP. We run experiments on vector-, grid- and graph-type data. In particular, this framework is capable of solving both graph- and node-level tasks for graph-type data. Therefore, MOLE has been experimentally proven to be universally applicable to different types of data.
Chat is not available.
Successful Page Load