Knowledge-Grounded Self-Rationalization via Extractive and Natural Language Explanations
{kind=link}
Abstract
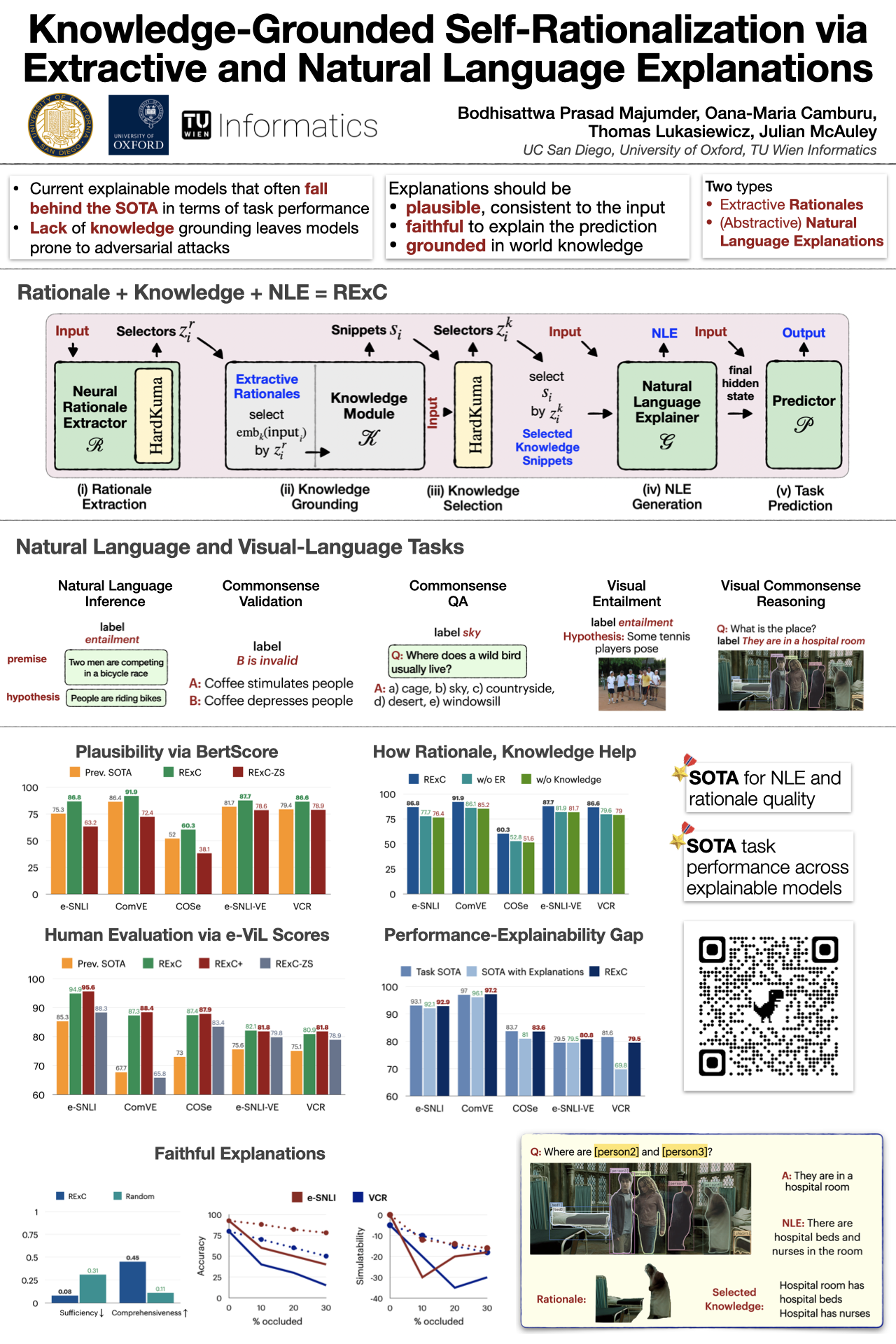
Models that generate extractive rationales (i.e., subsets of features) or natural language explanations (NLEs) for their predictions are important for explainable AI. While an extractive rationale provides a quick view of the features most responsible for a prediction, an NLE allows for a comprehensive description of the decision-making process behind a prediction. However, current models that generate the best extractive rationales or NLEs often fall behind the state-of-the-art (SOTA) in terms of task performance. In this work, we bridge this gap by introducing RExC, a self-rationalizing framework that grounds its predictions and two complementary types of explanations (NLEs and extractive rationales) in background knowledge. Our framework improves over previous methods by: (i) reaching SOTA task performance while also providing explanations, (ii) providing two types of explanations, while existing models usually provide only one type, and (iii) beating by a large margin the previous SOTA in terms of quality of both types of explanations. Furthermore, a perturbation analysis in RExC shows a high degree of association between explanations and predictions, a necessary property of faithful explanations.