Robin Hood and Matthew Effects: Differential Privacy Has Disparate Impact on Synthetic Data
{kind=link}
Abstract
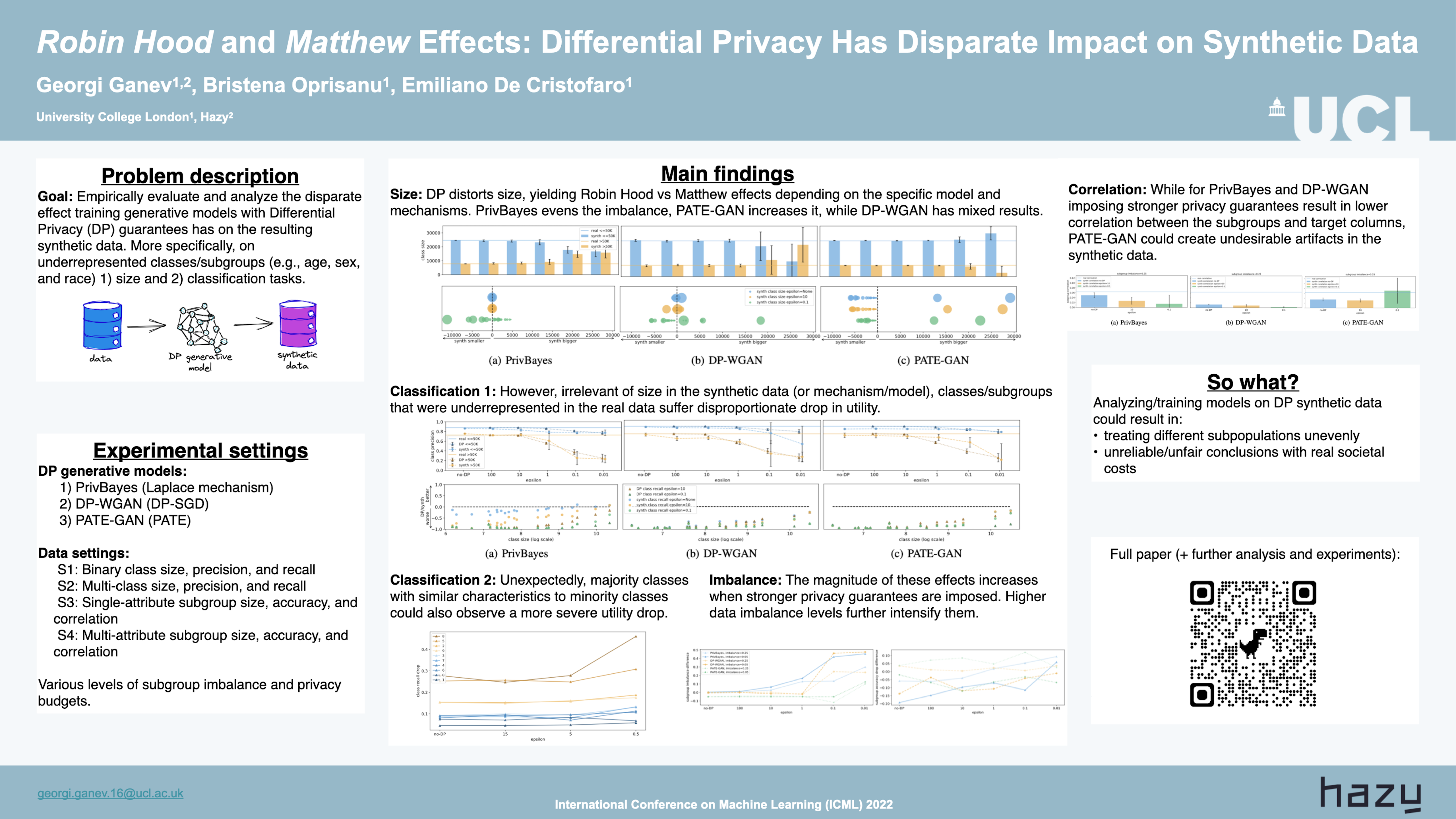
Generative models trained with Differential Privacy (DP) can be used to generate synthetic data while minimizing privacy risks. We analyze the impact of DP on these models vis-a-vis underrepresented classes/subgroups of data, specifically, studying: 1) the size of classes/subgroups in the synthetic data, and 2) the accuracy of classification tasks run on them. We also evaluate the effect of various levels of imbalance and privacy budgets. Our analysis uses three state-of-the-art DP models (PrivBayes, DP-WGAN, and PATE-GAN) and shows that DP yields opposite size distributions in the generated synthetic data. It affects the gap between the majority and minority classes/subgroups; in some cases by reducing it (a "Robin Hood" effect) and, in others, by increasing it (a "Matthew" effect). Either way, this leads to (similar) disparate impacts on the accuracy of classification tasks on the synthetic data, affecting disproportionately more the underrepresented subparts of the data. Consequently, when training models on synthetic data, one might incur the risk of treating different subpopulations unevenly, leading to unreliable or unfair conclusions.