Searching for BurgerFormer with Micro-Meso-Macro Space Design
{kind=link}
Abstract
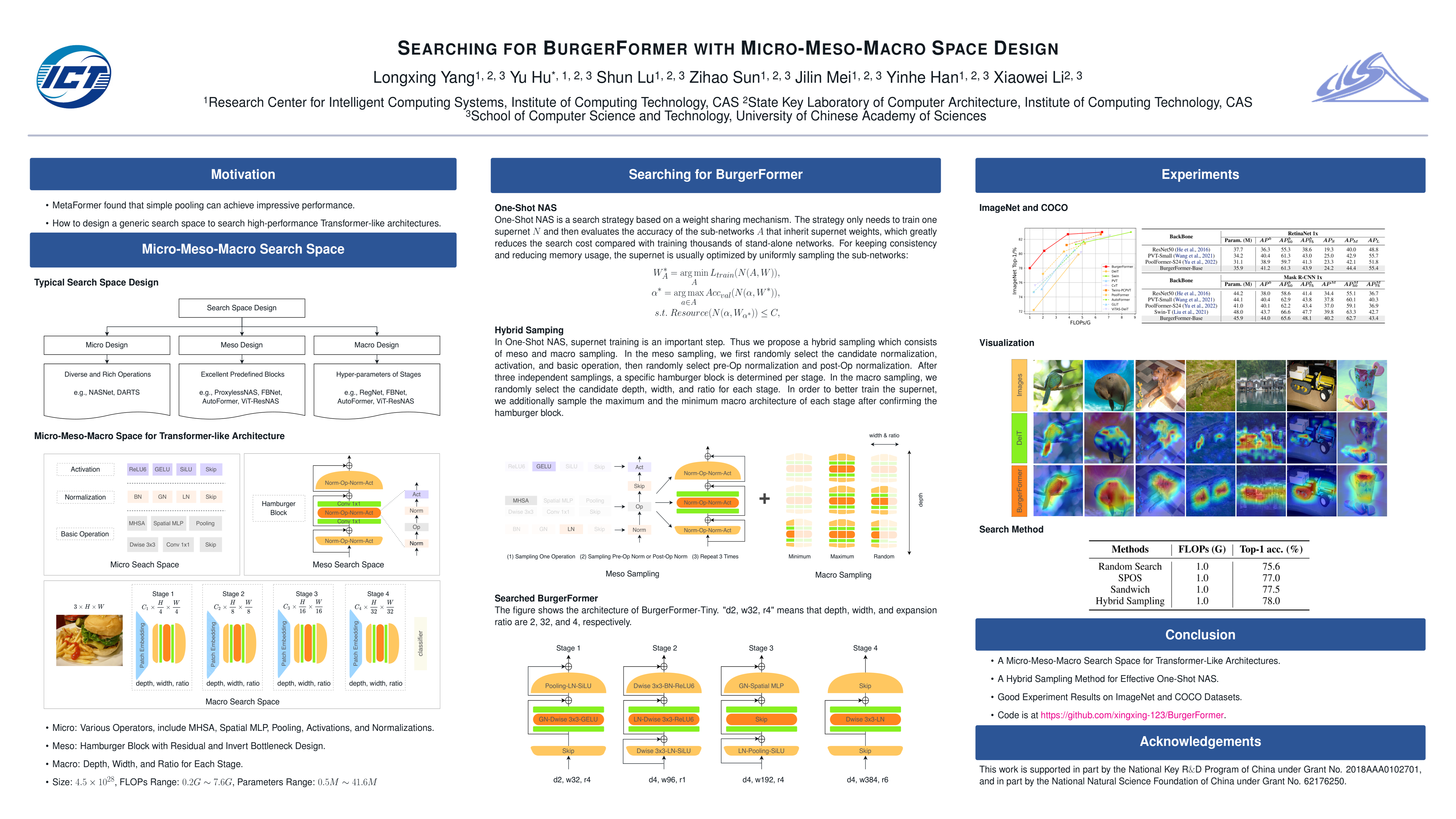
With the success of Transformers in the computer vision field, the automated design of vision Transformers has attracted significant attention. Recently, MetaFormer found that simple average pooling can achieve impressive performance, which naturally raises the question of how to design a search space to search diverse and high-performance Transformer-like architectures. By revisiting typical search spaces, we design micro-meso-macro space to search for Transformer-like architectures, namely BurgerFormer. Micro, meso, and macro correspond to the granularity levels of operation, block and stage, respectively. At the microscopic level, we enrich the atomic operations to include various normalizations, activation functions, and basic operations (e.g., multi-head self attention, average pooling). At the mesoscopic level, a hamburger structure is searched out as the basic BurgerFormer block. At the macroscopic level, we search for the depth, width, and expansion ratio of the network based on the multi-stage architecture. Meanwhile, we propose a hybrid sampling method for effectively training the supernet. Experimental results demonstrate that the searched BurgerFormer architectures achieve comparable even superior performance compared with current state-of-the-art Transformers on the ImageNet and COCO datasets. The codes can be available at https://github.com/xingxing-123/BurgerFormer.