Efficient Distributionally Robust Bayesian Optimization with Worst-case Sensitivity
{kind=link}
Abstract
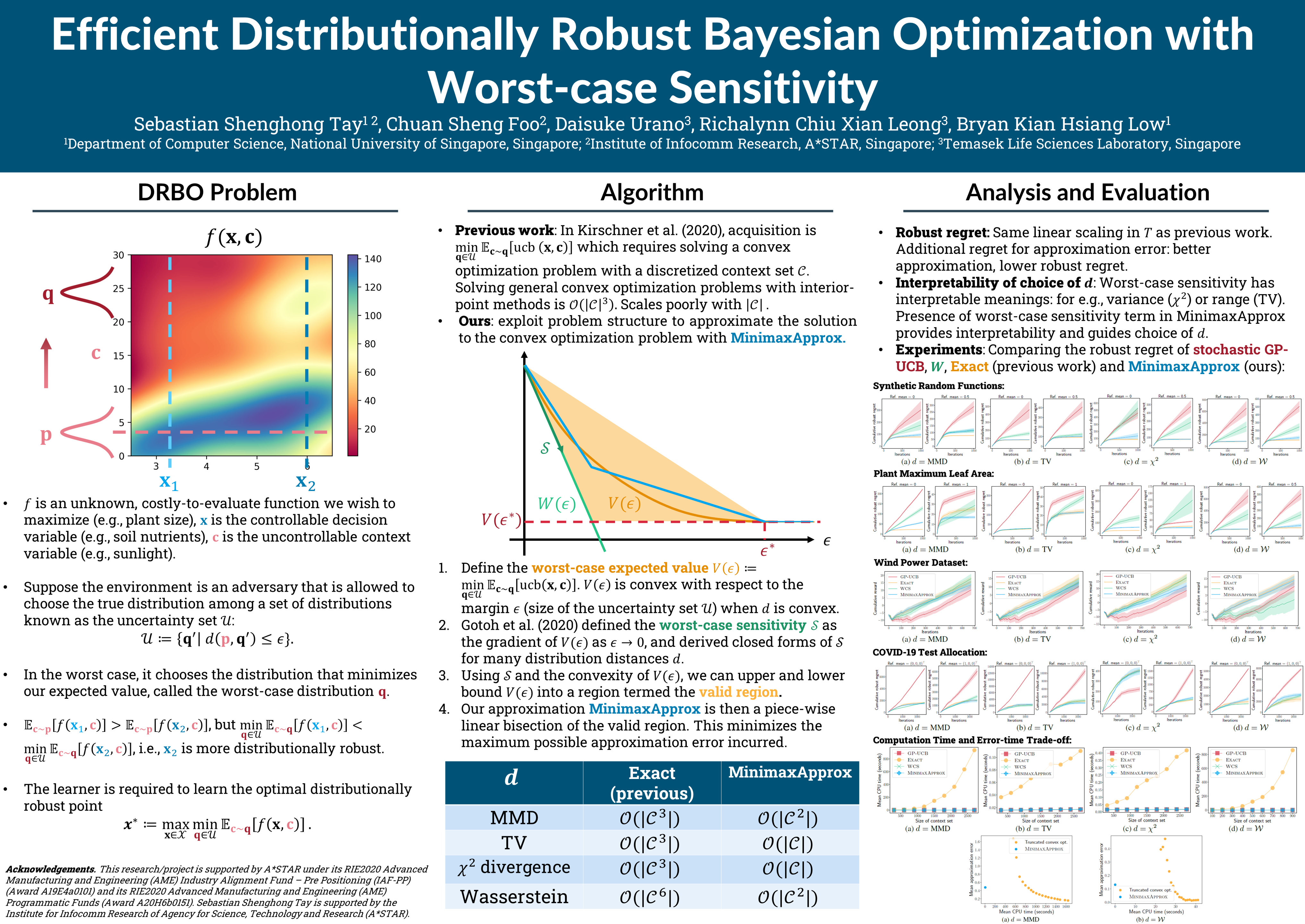
In distributionally robust Bayesian optimization (DRBO), an exact computation of the worst-case expected value requires solving an expensive convex optimization problem. We develop a fast approximation of the worst-case expected value based on the notion of worst-case sensitivity that caters to arbitrary convex distribution distances. We provide a regret bound for our novel DRBO algorithm with the fast approximation, and empirically show it is competitive with that using the exact worst-case expected value while incurring significantly less computation time. In order to guide the choice of distribution distance to be used with DRBO, we show that our approximation implicitly optimizes an objective close to an interpretable risk-sensitive value.