A$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
He Bai ⋅ Renjie Zheng ⋅ Junkun Chen ⋅ Mingbo Ma ⋅ Xintong Li ⋅ Liang Huang
Keywords:
APP: Language, Speech and Dialog
2022 Poster
{kind=link}
Abstract
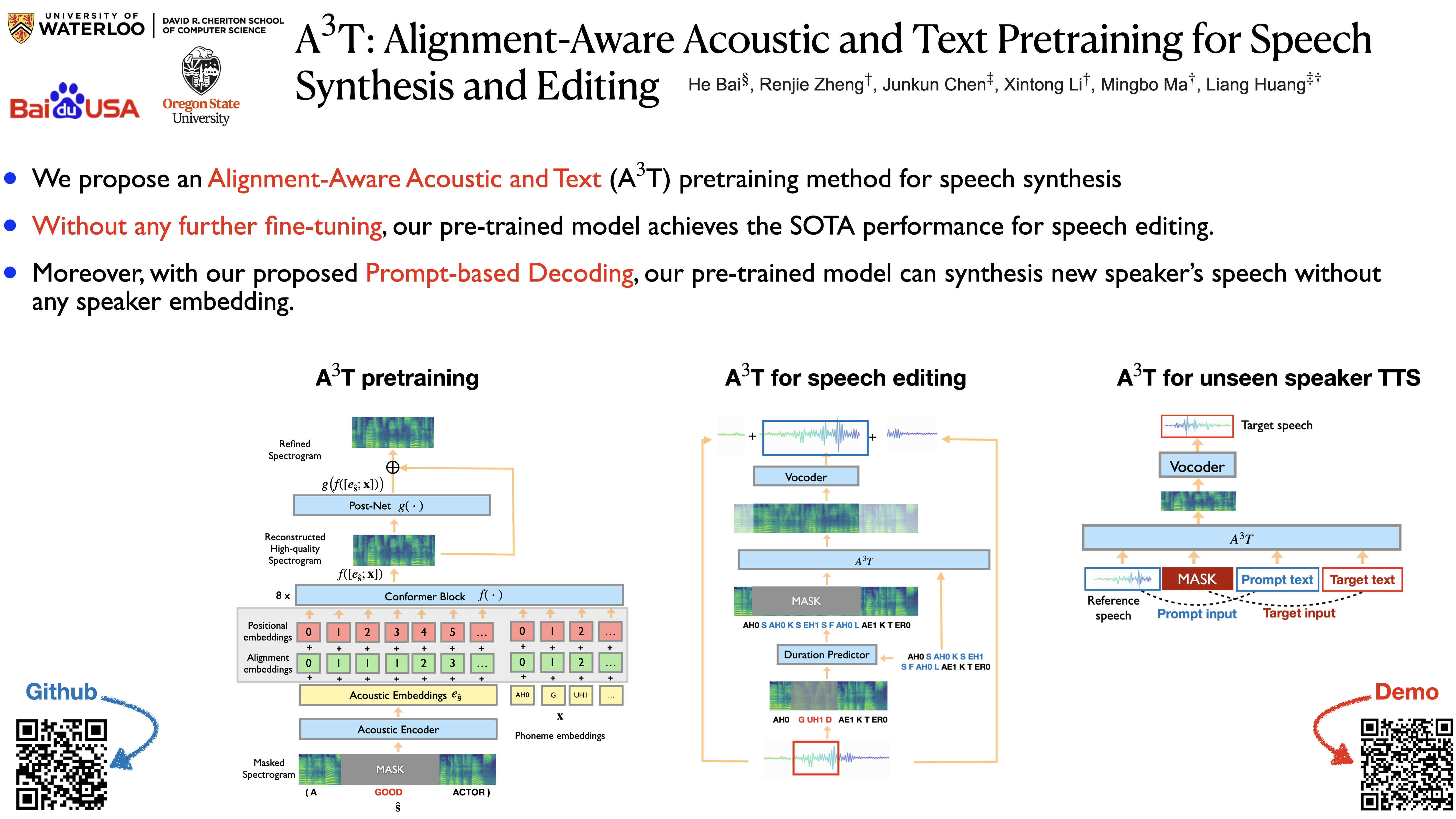
Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
Chat is not available.
Successful Page Load