Measuring dissimilarity with diffeomorphism invariance
Théophile Cantelobre ⋅ Carlo Ciliberto ⋅ Benjamin Guedj ⋅ Alessandro Rudi
2022 Poster
{kind=link}
Abstract
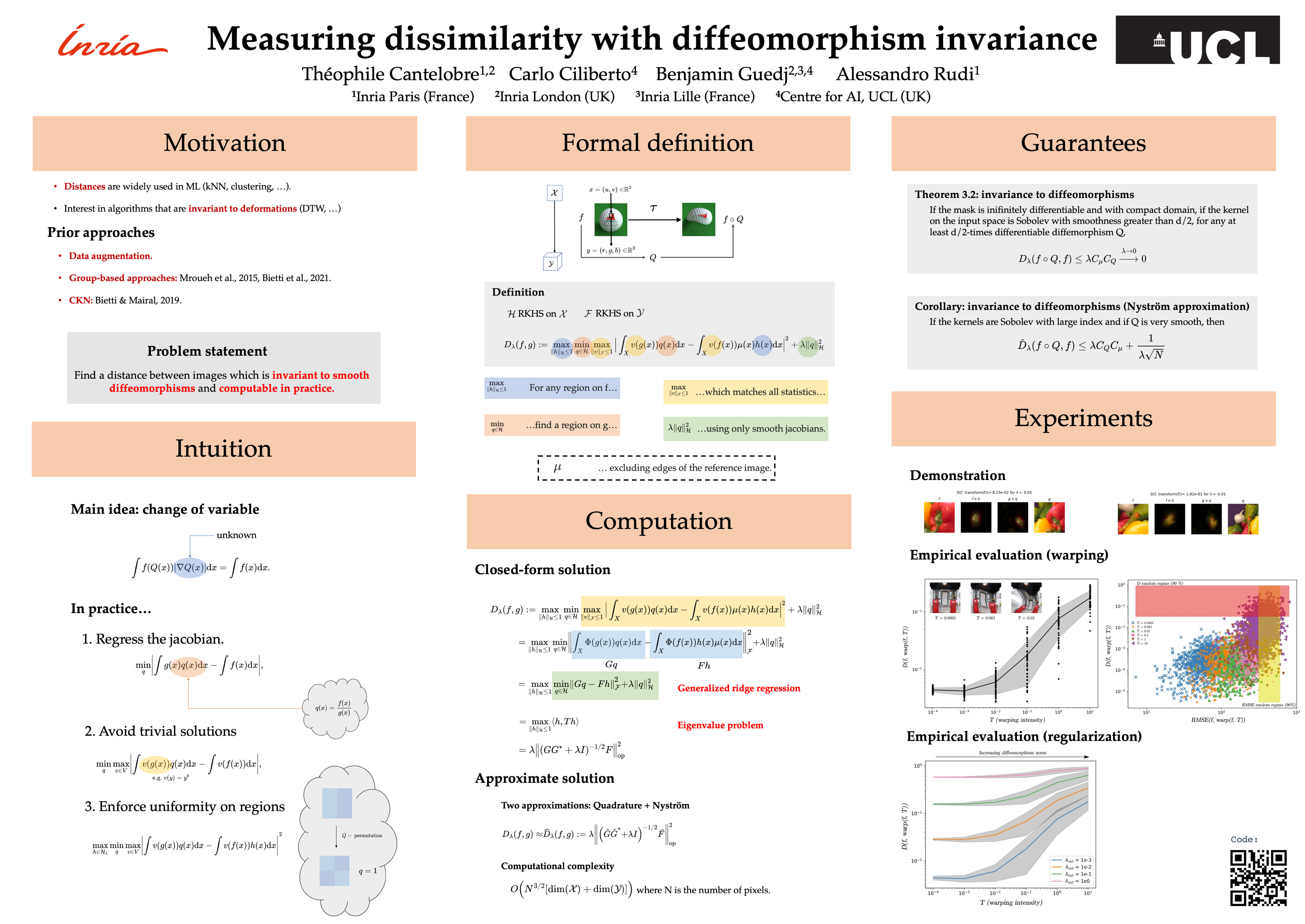
Measures of similarity (or dissimilarity) are a key ingredient to many machine learning algorithms. We introduce DID, a pairwise dissimilarity measure applicable to a wide range of data spaces, which leverages the data's internal structure to be invariant to diffeomorphisms. We prove that DID enjoys properties which make it relevant for theoretical study and practical use. By representing each datum as a function, DID is defined as the solution to an optimization problem in a Reproducing Kernel Hilbert Space and can be expressed in closed-form. In practice, it can be efficiently approximated via Nyström sampling. Empirical experiments support the merits of DID.
Chat is not available.
Successful Page Load