Data Scaling Laws in NMT: The Effect of Noise and Architecture
{kind=link}
Abstract
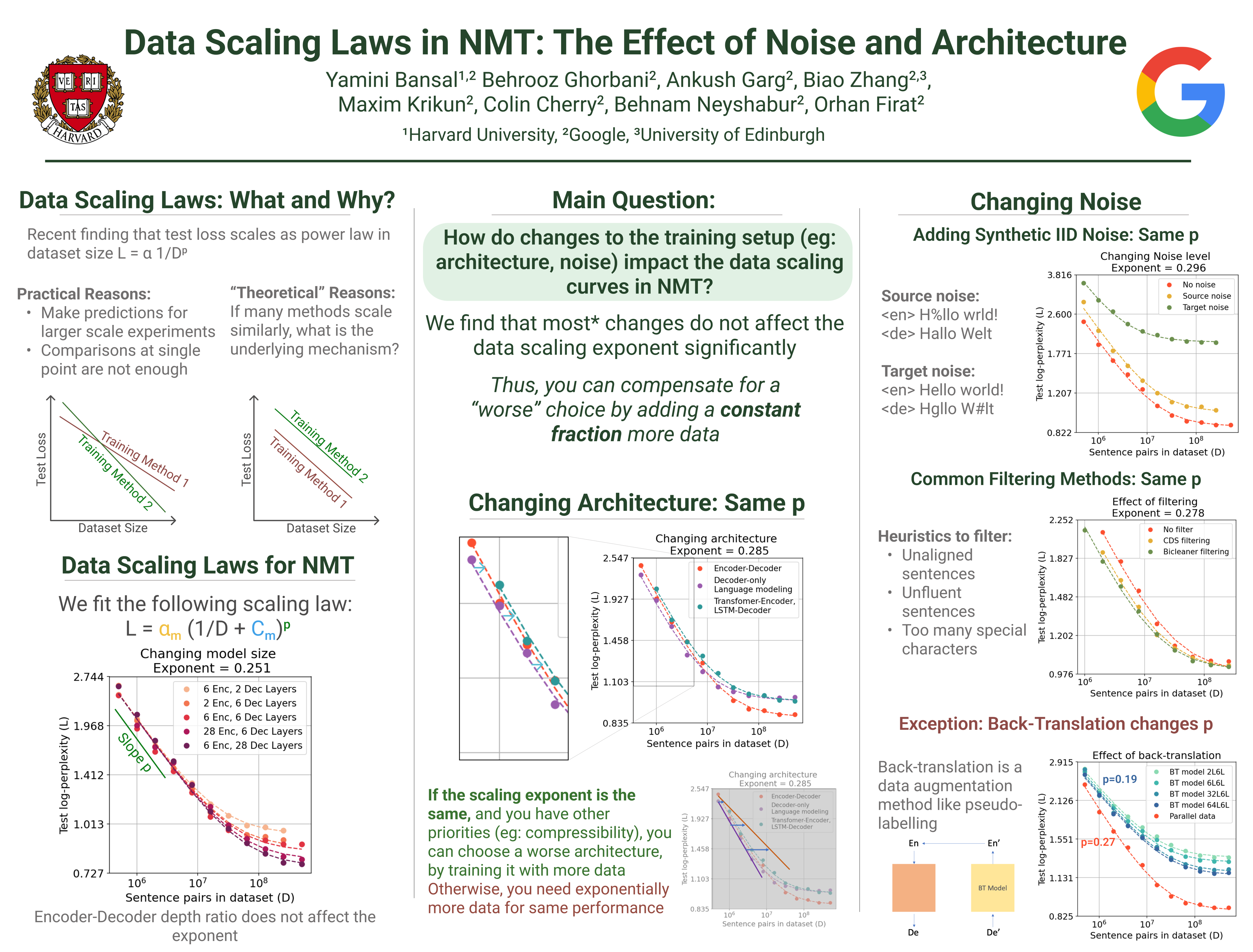
In this work, we study the effect of varying the architecture and training data quality on the data scaling properties of Neural Machine Translation (NMT). First, we establish that the test loss of encoder-decoder transformer models scales as a power law in the number of training samples, with a dependence on the model size. Then, we systematically vary aspects of the training setup to understand how they impact the data scaling laws. In particular, we change the following (1) Architecture and task setup: We compare to a transformer-LSTM hybrid, and a decoder-only transformer with a language modeling loss (2) Noise level in the training distribution: We experiment with filtering, and adding iid synthetic noise. In all the above cases, we find that the data scaling exponents are minimally impacted, suggesting that marginally worse architectures or training data can be compensated for by adding more data. Lastly, we find that using back-translated data instead of parallel data, can significantly degrade the scaling exponent.