What Dense Graph Do You Need for Self-Attention?
Yuxin Wang ⋅ Chu-Tak Lee ⋅ Qipeng Guo ⋅ Zhangyue Yin ⋅ yunhua zhou ⋅ Xuanjing Huang ⋅ Xipeng Qiu
2022 Poster
{kind=link}
Abstract
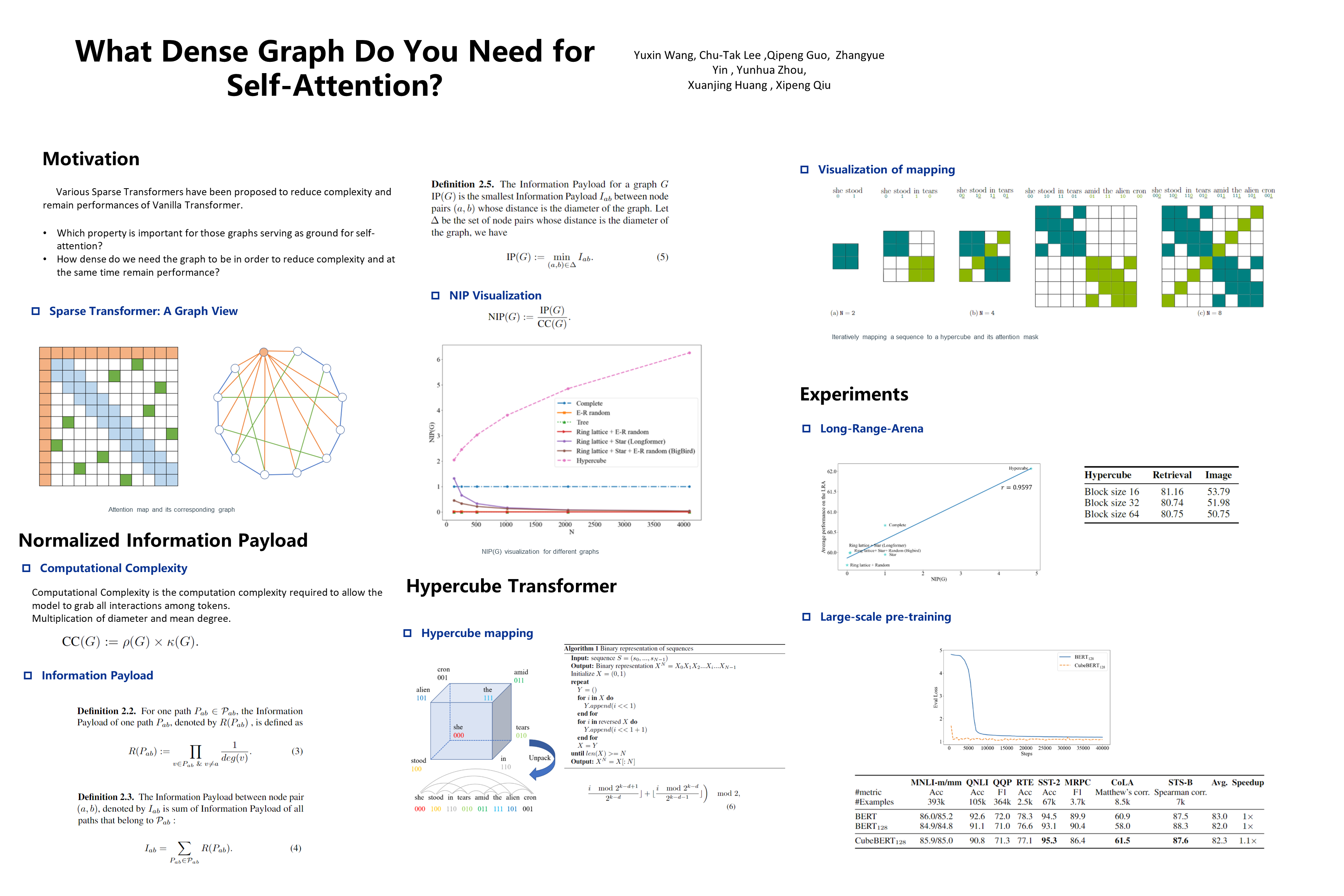
Transformers have made progress in miscellaneous tasks, but suffer from quadratic computational and memory complexities. Recent works propose sparse transformers with attention on sparse graphs to reduce complexity and remain strong performance. While effective, the crucial parts of how dense a graph needs to be to perform well are not fully explored. In this paper, we propose Normalized Information Payload (NIP), a graph scoring function measuring information transfer on graph, which provides an analysis tool for trade-offs between performance and complexity. Guided by this theoretical analysis, we present Hypercube Transformer, a sparse transformer that models token interactions in a hypercube and shows comparable or even better results with vanilla transformer while yielding $O(N\log N)$ complexity with sequence length $N$. Experiments on tasks requiring various sequence lengths lay validation for our graph function well.
Chat is not available.
Successful Page Load