ASAP.SGD: Instance-based Adaptiveness to Staleness in Asynchronous SGD
Karl Bäckström ⋅ Marina Papatriantafilou ⋅ Philippas Tsigas
2022 Poster
{kind=link}
Abstract
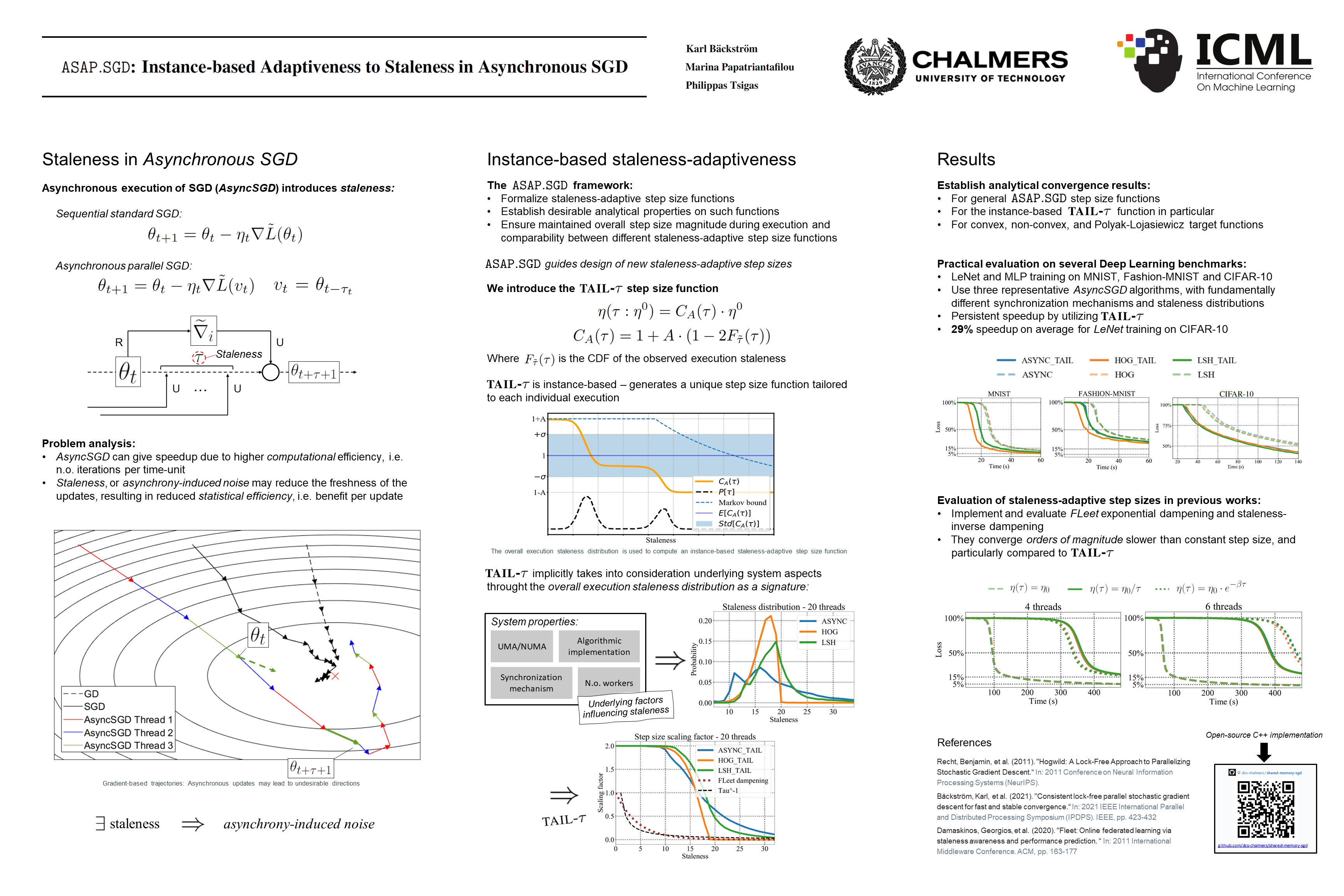
Concurrent algorithmic implementations of Stochastic Gradient Descent (SGD) give rise to critical questions for compute-intensive Machine Learning (ML). Asynchrony implies speedup in some contexts, and challenges in others, as stale updates may lead to slower, or non-converging executions. While previous works showed asynchrony-adaptiveness can improve stability and speedup by reducing the step size for stale updates according to static rules, there is no one-size-fits-all adaptation rule, since the optimal strategy depends on several factors. We introduce (i)~$\mathtt{ASAP.SGD}$, an analytical framework capturing necessary and desired properties of staleness-adaptive step size functions and (ii)~\textsc{tail}-$\tau$, a method for utilizing key properties of the \emph{execution instance}, generating a tailored strategy that not only dampens the impact of stale updates, but also leverages fresh ones. We recover convergence bounds for adaptiveness functions satisfying the $\mathtt{ASAP.SGD}$ conditions for general, convex and non-convex problems, and establish novel bounds for ones satisfying the Polyak-Lojasiewicz property. We evaluate \textsc{tail}-$\tau$ with representative \emph{AsyncSGD} concurrent algorithms, for Deep Learning problems, showing \textsc{tail}-$\tau$ is a vital complement to \emph{AsyncSGD}, with (i)~persistent speedup in wall-clock convergence time in the parallelism spectrum, (ii)~considerably lower risk of non-convergence, as well as (iii)~precision levels for which original SGD implementations fail.
Chat is not available.
Successful Page Load