Self-supervised learning with random-projection quantizer for speech recognition
{kind=link}
Abstract
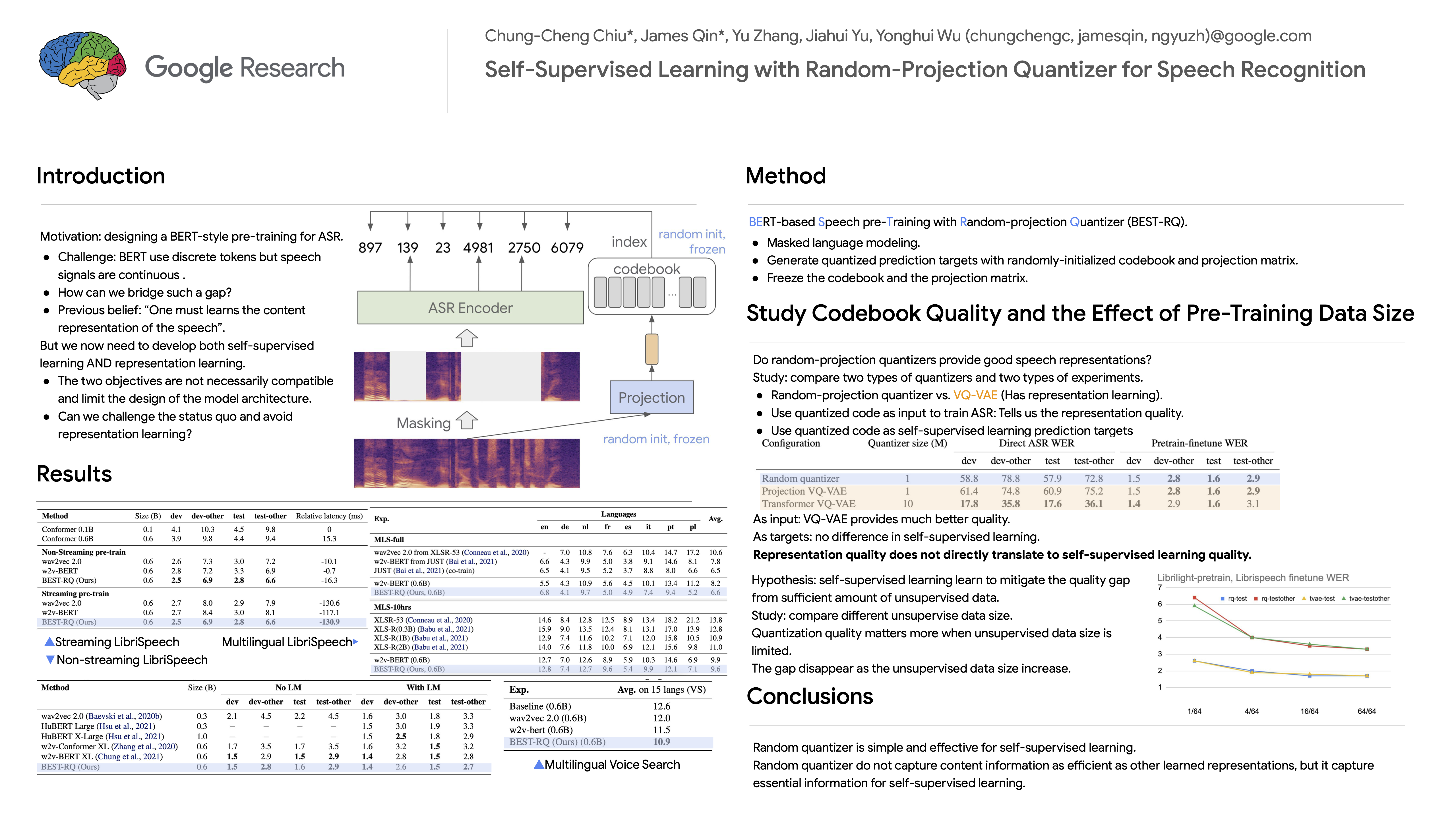
We present a simple and effective self-supervised learning approach for speech recognition. The approach learns a model to predict the masked speech signals, in the form of discrete labels generated with a random-projection quantizer. In particular the quantizer projects speech inputs with a randomly initialized matrix, and does a nearest-neighbor lookup in a randomly-initialized codebook. Neither the matrix nor the codebook are updated during self-supervised learning. Since the random-projection quantizer is not trained and is separated from the speech recognition model, the design makes the approach flexible and is compatible with universal speech recognition architecture. On LibriSpeech our approach achieves similar word-error-rates as previous work using self-supervised learning with non-streaming models, and provides lower word-error-rates than previous work with streaming models. On multilingual tasks the approach also provides significant improvement over wav2vec 2.0 and w2v-BERT.