Multiple-Play Stochastic Bandits with Shareable Finite-Capacity Arms
{kind=link}
Abstract
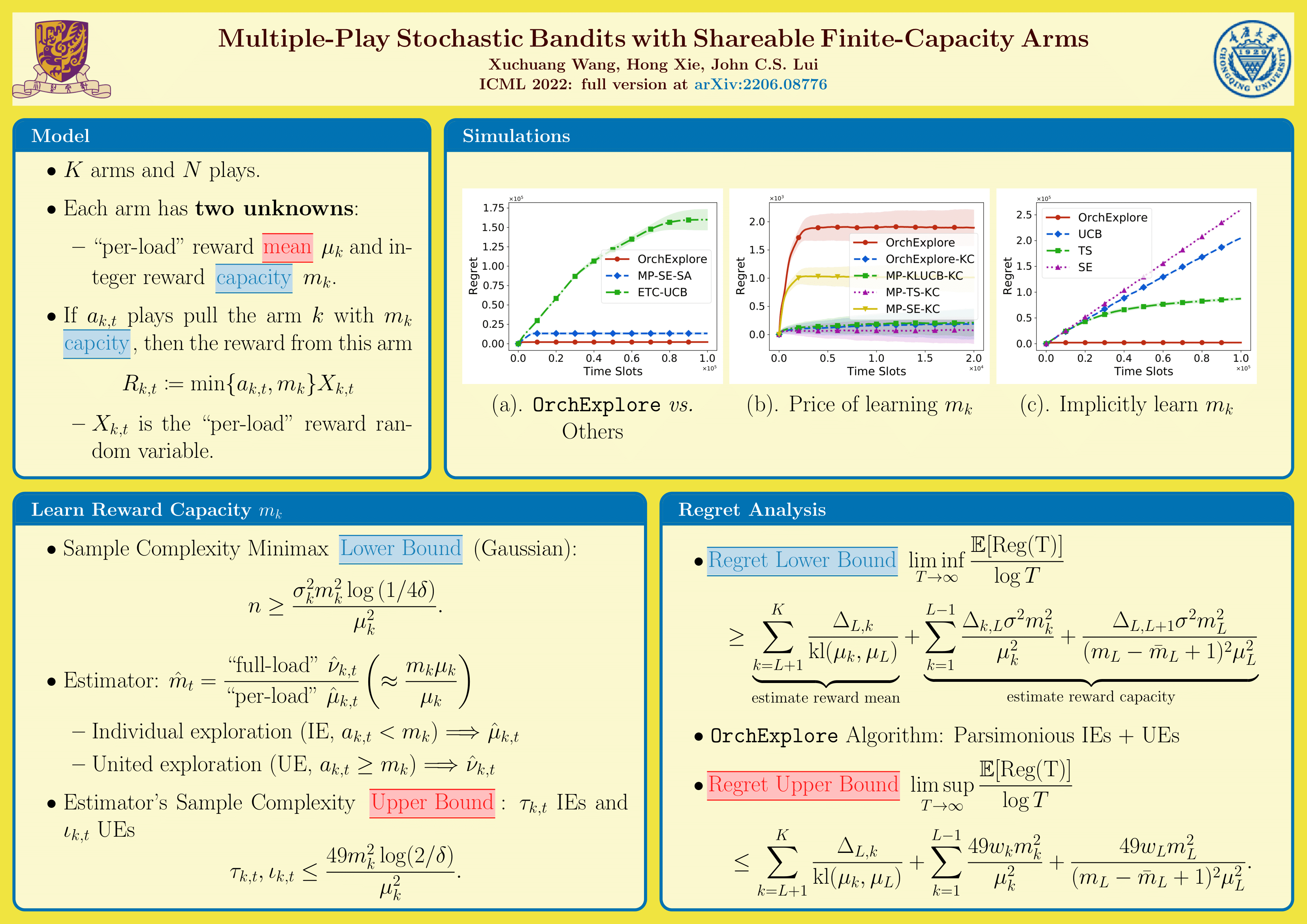
We generalize the multiple-play multi-armed bandits (MP-MAB) problem with a shareable arms setting, in which several plays can share the same arm. Furthermore, each shareable arm has a finite reward capacity and a “per-load” reward distribution, both of which are unknown to the learner. The reward from a shareable arm is load-dependent, which is the “per-load” reward multiplying either the number of plays pulling the arm, or its reward capacity when the number of plays exceeds the capacity limit. When the “per-load” reward follows a Gaussian distribution, we prove a sample complexity lower bound of learning the capacity from load-dependent rewards and also a regret lower bound of this new MP-MAB problem. We devise a capacity estimator whose sample complexity upper bound matches the lower bound in terms of reward means and capacities. We also propose an online learning algorithm to address the problem and prove its regret upper bound. This regret upper bound's first term is the same as regret lower bound's, and its second and third terms also evidently correspond to lower bound's. Extensive experiments validate our algorithm’s performance and also its gain in 5G & 4G base station selection.