Not All Poisons are Created Equal: Robust Training against Data Poisoning
{kind=link}
Abstract
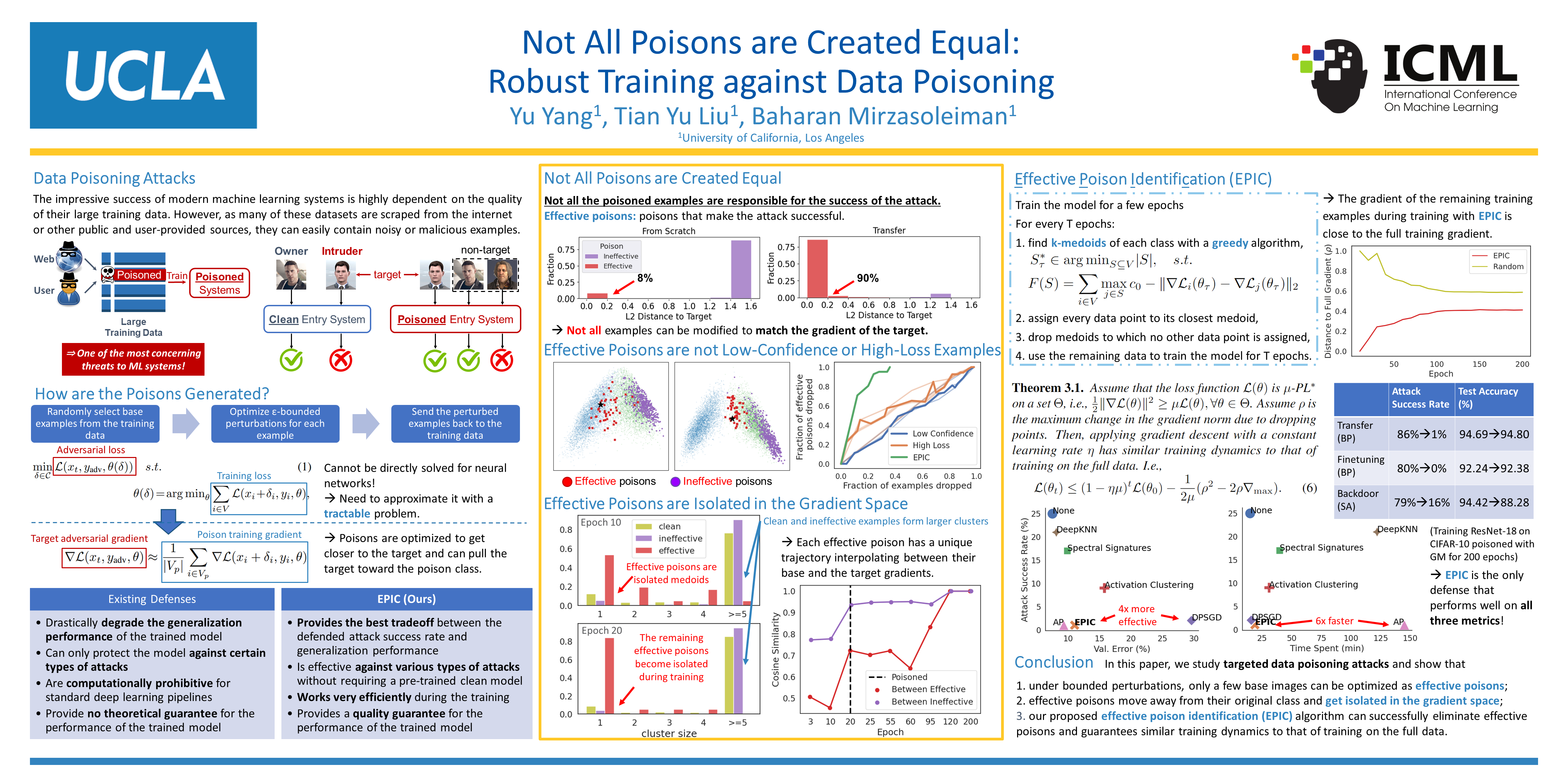
Data poisoning causes misclassification of test time target examples, by injecting maliciously crafted samples in the training data. Existing defenses are often effective only against a specific type of targeted attack, significantly degrade the generalization performance, or are prohibitive for standard deep learning pipelines. In this work, we propose an efficient defense mechanism that significantly reduces the success rate of various data poisoning attacks, and provides theoretical guarantees for the performance of the model. Targeted attacks work by adding bounded perturbations to a randomly selected subset of training data to match the targets’ gradient or representation. We show that: (i) under bounded perturbations, only a number of poisons can be optimized to have a gradient that is close enough to that of the target and make the attack successful; (ii) such effective poisons move away from their original class and get isolated in the gradient space; (iii) dropping examples in low-density gradient regions during training can successfully eliminate the effective poisons, and guarantees similar training dynamics to that of training on full data. Our extensive experiments show that our method significantly decreases the success rate of state-of-the-art targeted attacks, including Gradient Matching and Bullseye Polytope, and easily scales to large datasets.