Detecting Corrupted Labels Without Training a Model to Predict
{kind=link}
Abstract
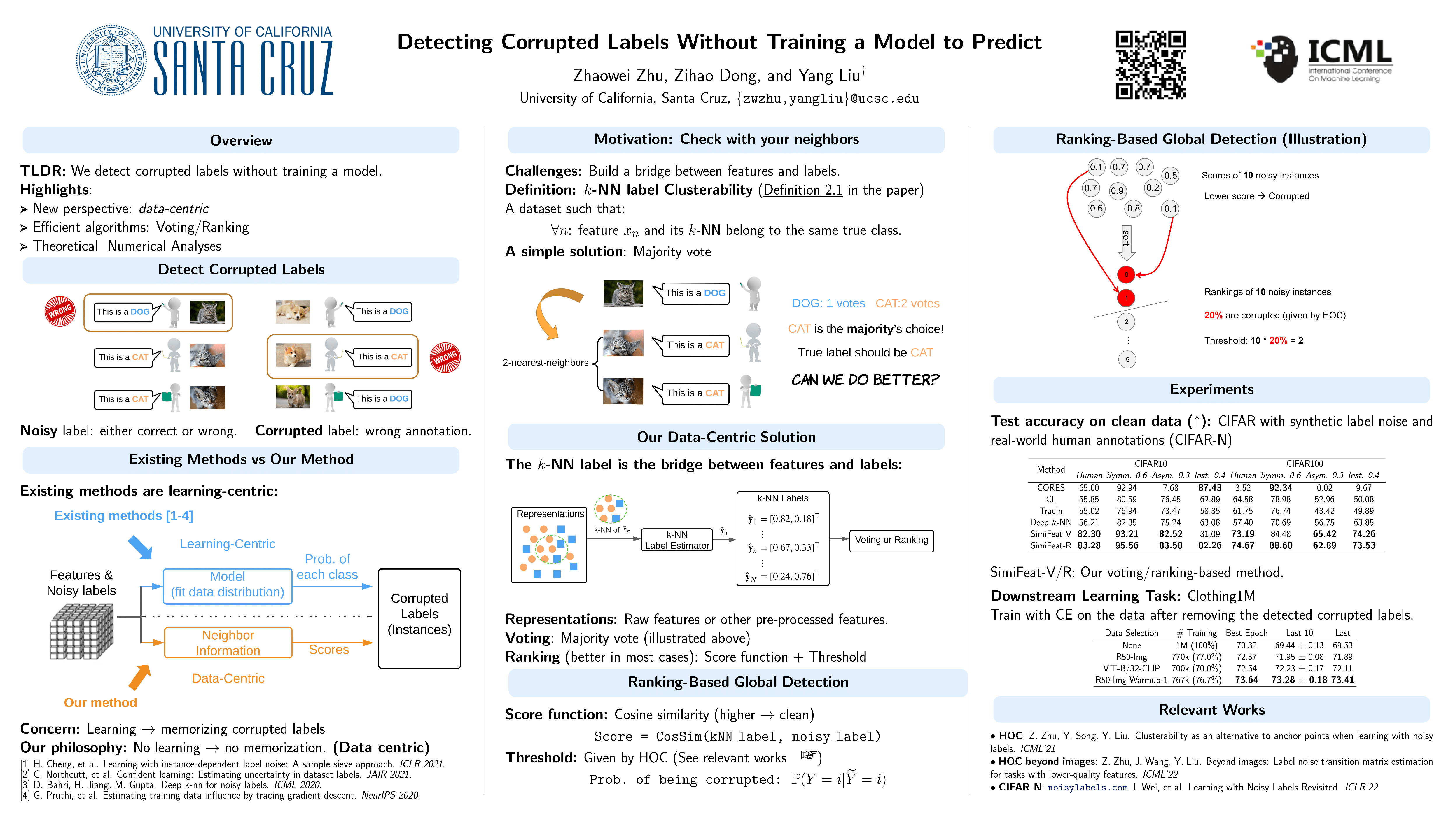
Label noise in real-world datasets encodes wrong correlation patterns and impairs the generalization of deep neural networks (DNNs). It is critical to find efficient ways to detect corrupted patterns. Current methods primarily focus on designing robust training techniques to prevent DNNs from memorizing corrupted patterns. These approaches often require customized training processes and may overfit corrupted patterns, leading to a performance drop in detection. In this paper, from a more data-centric perspective, we propose a training-free solution to detect corrupted labels. Intuitively, closer'' instances are more likely to share the same clean label. Based on the neighborhood information, we propose two methods: the first one useslocal voting" via checking the noisy label consensuses of nearby features. The second one is a ranking-based approach that scores each instance and filters out a guaranteed number of instances that are likely to be corrupted. We theoretically analyze how the quality of features affects the local voting and provide guidelines for tuning neighborhood size. We also prove the worst-case error bound for the ranking-based method. Experiments with both synthetic and real-world label noise demonstrate our training-free solutions consistently and significantly improve most of the training-based baselines. Code is available at github.com/UCSC-REAL/SimiFeat.