Feature Space Particle Inference for Neural Network Ensembles
{kind=link}
Abstract
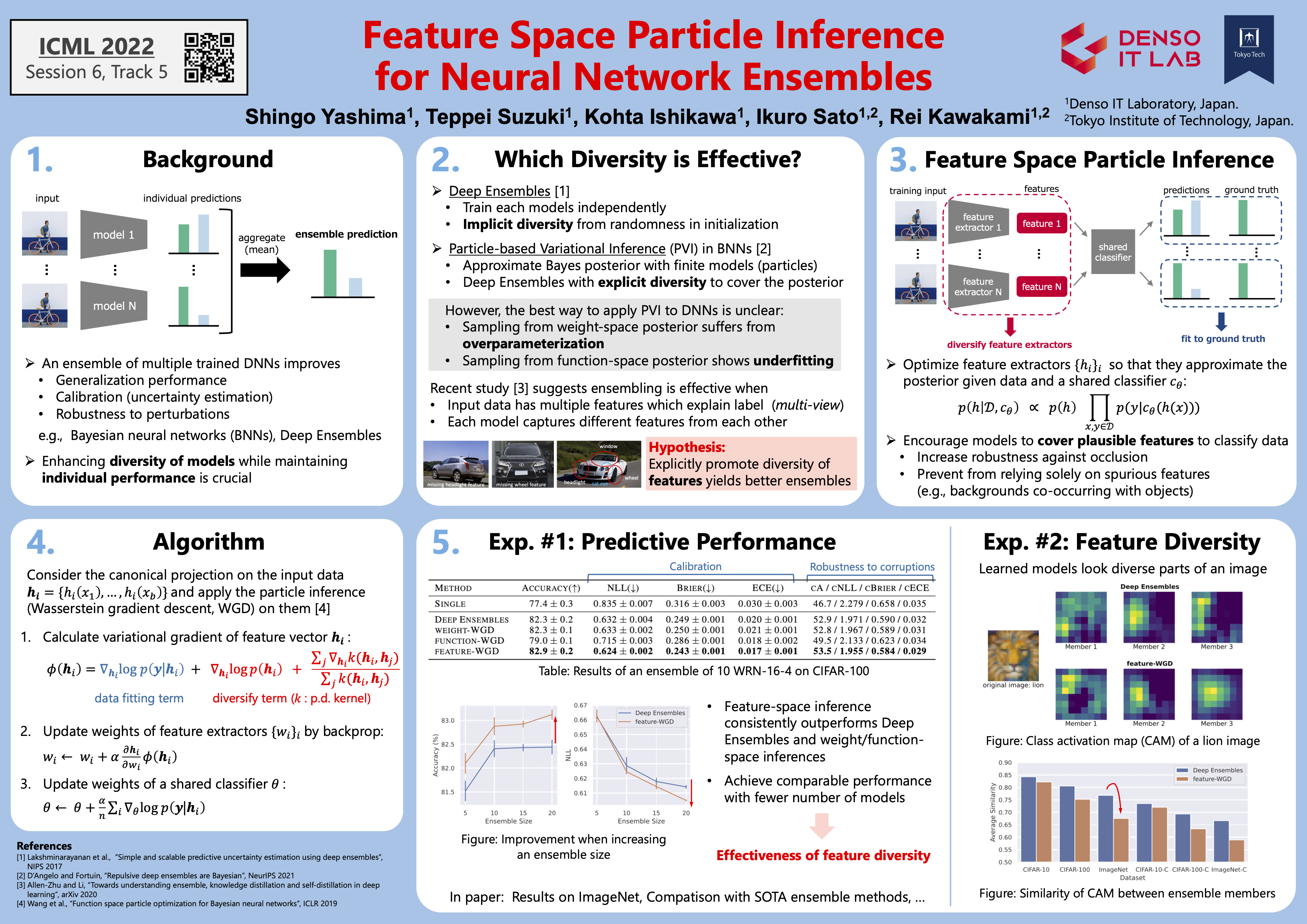
Ensembles of deep neural networks demonstrate improved performance over single models. For enhancing the diversity of ensemble members while keeping their performance, particle-based inference methods offer a promising approach from a Bayesian perspective. However, the best way to apply these methods to neural networks is still unclear: seeking samples from the weight-space posterior suffers from inefficiency due to the over-parameterization issues, while seeking samples directly from the function-space posterior often leads to serious underfitting. In this study, we propose to optimize particles in the feature space where activations of a specific intermediate layer lie to alleviate the abovementioned difficulties. Our method encourages each member to capture distinct features, which are expected to increase the robustness of the ensemble prediction. Extensive evaluation on real-world datasets exhibits that our model significantly outperforms the gold-standard Deep Ensembles on various metrics, including accuracy, calibration, and robustness.