Does the Data Induce Capacity Control in Deep Learning?
{kind=link}
Abstract
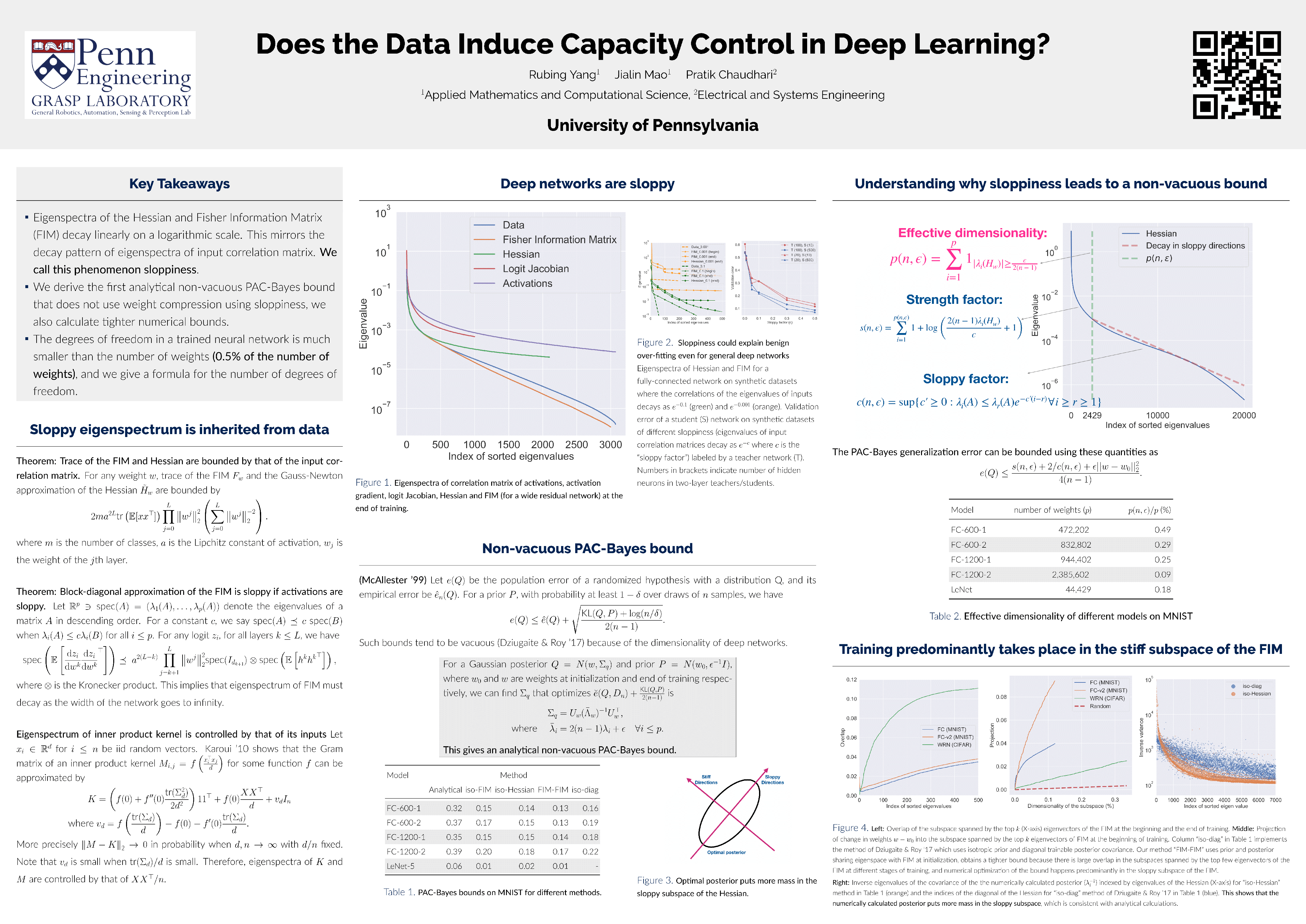
We show that the input correlation matrix of typical classification datasets has an eigenspectrum where, after a sharp initial drop, a large number of small eigenvalues are distributed uniformly over an exponentially large range. This structure is mirrored in a network trained on this data: we show that the Hessian and the Fisher Information Matrix (FIM) have eigenvalues that are spread uniformly over exponentially large ranges. We call such eigenspectra ``sloppy'' because sets of weights corresponding to small eigenvalues can be changed by large magnitudes without affecting the loss. Networks trained on atypical datasets with non-sloppy inputs do not share these traits and deep networks trained on such datasets generalize poorly. Inspired by this, we study the hypothesis that sloppiness of inputs aids generalization in deep networks. We show that if the Hessian is sloppy, we can compute non-vacuous PAC-Bayes generalization bounds analytically. By exploiting our empirical observation that training predominantly takes place in the non-sloppy subspace of the FIM, we develop data-distribution dependent PAC-Bayes priors that lead to accurate generalization bounds using numerical optimization.