Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning
{kind=link}
Abstract
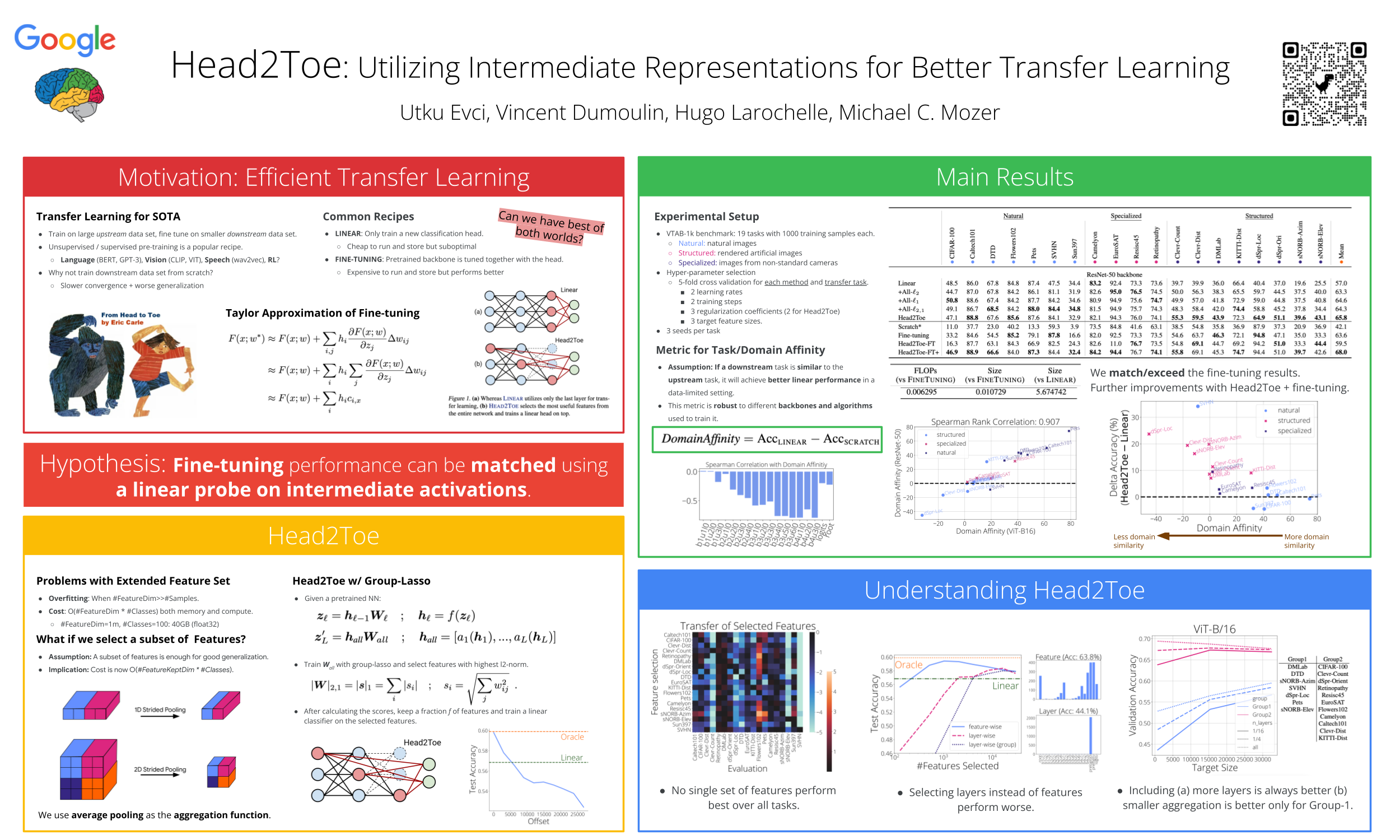
Transfer-learning methods aim to improve performance in a data-scarce target domain using a model pretrained on a data-rich source domain. A cost-efficient strategy, linear probing, involves freezing the source model and training a new classification head for the target domain. This strategy is outperformed by a more costly but state-of-the-art method -- fine-tuning all parameters of the source model to the target domain -- possibly because fine-tuning allows the model to leverage useful information from intermediate layers which is otherwise discarded by the later previously trained layers. We explore the hypothesis that these intermediate layers might be directly exploited. We propose a method, Head-to-Toe probing (Head2Toe), that selects features from all layers of the source model to train a classification head for the target-domain. In evaluations on the Visual Task Adaptation Benchmark-1k, Head2Toe matches performance obtained with fine-tuning on average while reducing training and storage cost hundred folds or more, but critically, for out-of-distribution transfer, Head2Toe outperforms fine-tuning. Code used in our experiments can be found in supplementary materials.