Constrained Variational Policy Optimization for Safe Reinforcement Learning
{kind=link}
Abstract
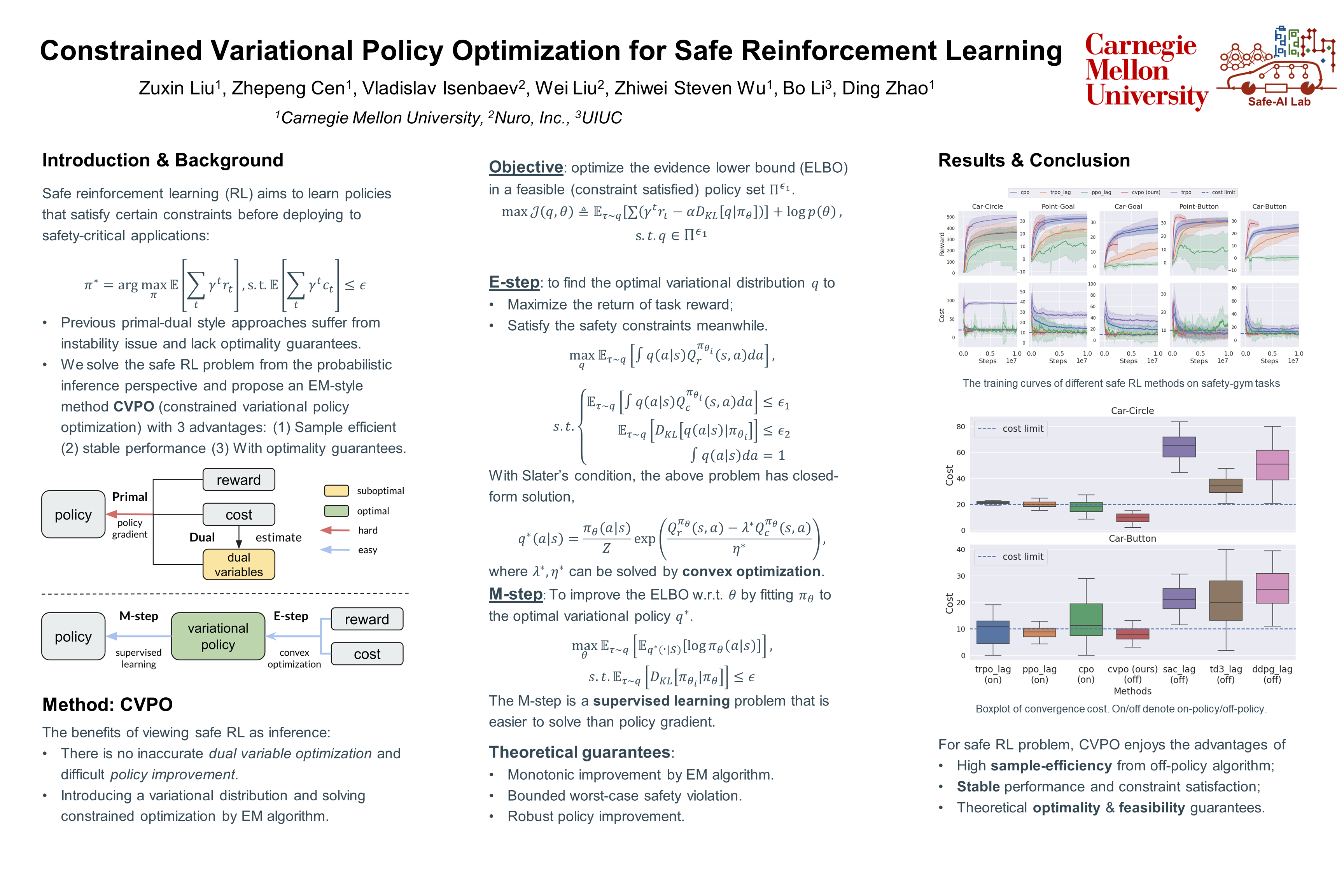
Safe reinforcement learning (RL) aims to learn policies that satisfy certain constraints before deploying them to safety-critical applications.Previous primal-dual style approaches suffer from instability issues and lack optimality guarantees. This paper overcomes the issues from the perspective of probabilistic inference. We introduce a novel Expectation-Maximization approach to naturally incorporate constraints during the policy learning: 1) a provable optimal non-parametric variational distribution could be computed in closed form after a convex optimization (E-step); 2) the policy parameter is improved within the trust region based on the optimal variational distribution (M-step).The proposed algorithm decomposes the safe RL problem into a convex optimization phase and a supervised learning phase, which yields a more stable training performance.A wide range of experiments on continuous robotic tasks shows that the proposed method achieves significantly better constraint satisfaction performance and better sample efficiency than baselines.The code is available at https://github.com/liuzuxin/cvpo-safe-rl.