Breaking the $\sqrt{T}$ Barrier: Instance-Independent Logarithmic Regret in Stochastic Contextual Linear Bandits
Avishek Ghosh ⋅ Abishek Sankararaman
2022 Poster
{kind=link}
Abstract
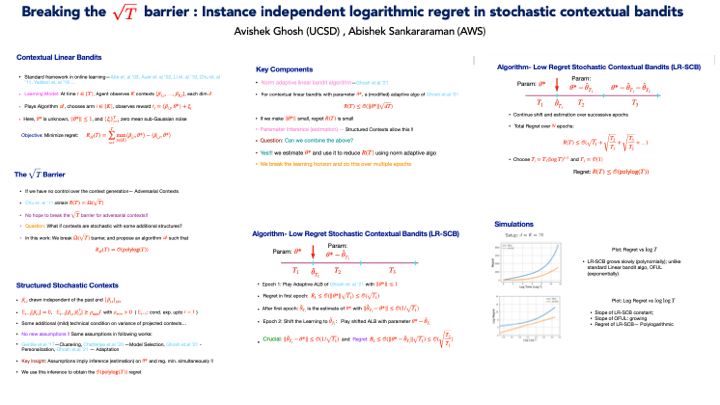
We prove an instance independent (poly) logarithmic regret for stochastic contextual bandits with linear payoff. Previously, in \cite{chu2011contextual}, a lower bound of $\mathcal{O}(\sqrt{T})$ is shown for the contextual linear bandit problem with arbitrary (adversarily chosen) contexts. In this paper, we show that stochastic contexts indeed help to reduce the regret from $\sqrt{T}$ to $\polylog(T)$. We propose Low Regret Stochastic Contextual Bandits (\texttt{LR-SCB}), which takes advantage of the stochastic contexts and performs parameter estimation (in $\ell_2$ norm) and regret minimization simultaneously. \texttt{LR-SCB} works in epochs, where the parameter estimation of the previous epoch is used to reduce the regret of the current epoch. The (poly) logarithmic regret of \texttt{LR-SCB} stems from two crucial facts: (a) the application of a norm adaptive algorithm to exploit the parameter estimation and (b) an analysis of the shifted linear contextual bandit algorithm, showing that shifting results in increasing regret. We have also shown experimentally that stochastic contexts indeed incurs a regret that scales with $\polylog(T)$.
Chat is not available.
Successful Page Load