In defense of dual-encoders for neural ranking
{kind=link}
Abstract
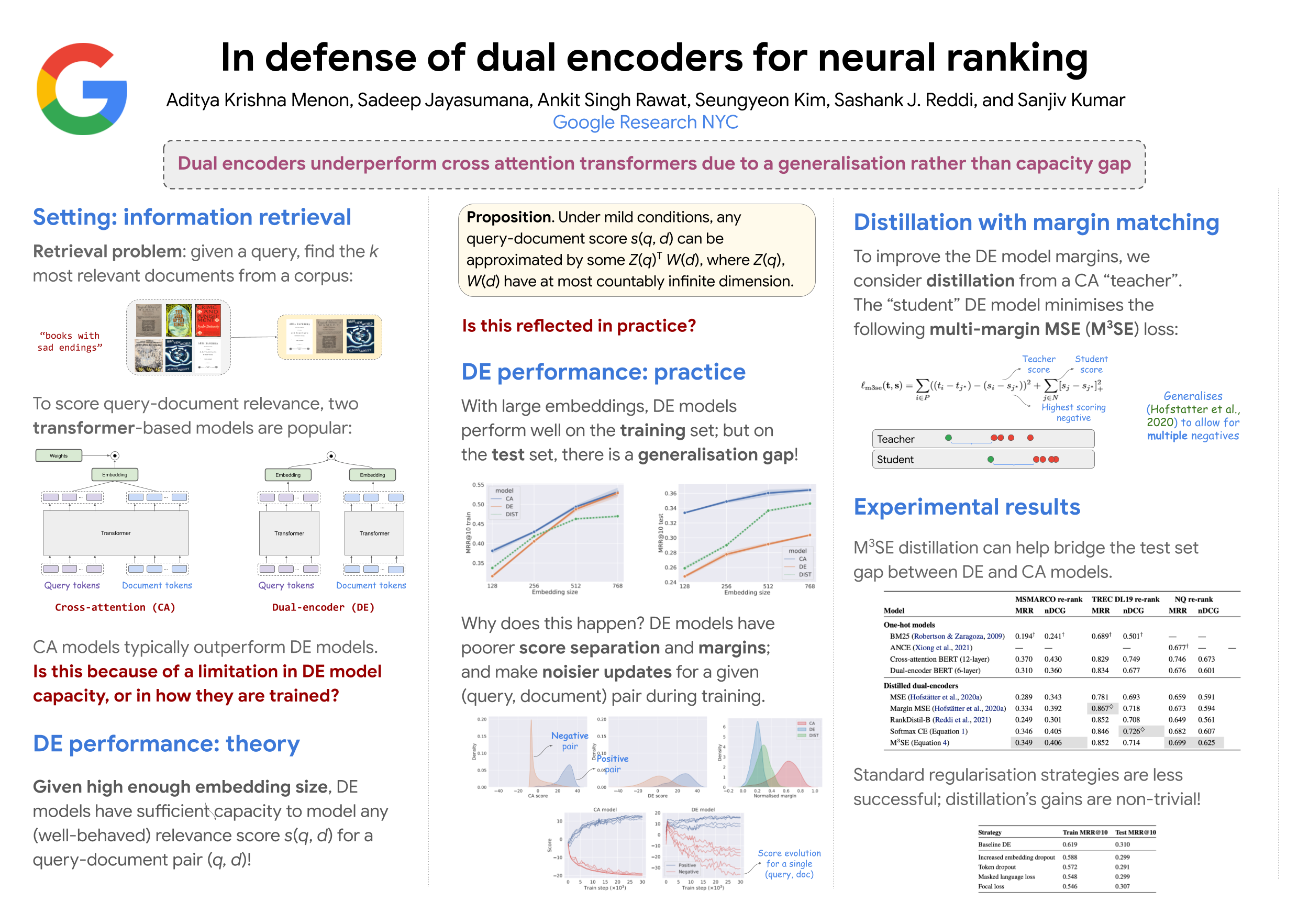
Transformer-based models such as BERT have proven successful in information retrieval problem, which seek to identify relevant documents for a given query. There are two broad flavours of such models: cross-attention (CA) models, which learn a joint embedding for the query and document, and dual-encoder (DE) models, which learn separate embeddings for the query and document. Empirically, CA models are often found to be more accurate, which has motivated a series of works seeking to bridge this gap. However, a more fundamental question remains less explored: does this performance gap reflect an inherent limitation in the capacity of DE models, or a limitation in the training of such models? And does such an understanding suggest a principled means of improving DE models? In this paper, we study these questions, with three contributions. First, we establish theoretically that with a sufficiently large embedding dimension, DE models have the capacity to model a broad class of score distributions. Second, we show empirically that on real-world problems, DE models may overfit to spurious correlations in the training set, and thus under-perform on test samples. To mitigate this behaviour, we propose a suitable distillation strategy, and confirm its practical efficacy on the MSMARCO-Passage and Natural Questions benchmarks.