Detecting Adversarial Examples Is (Nearly) As Hard As Classifying Them
Florian Tramer
Keywords:
T: Everything Else
SA: Trustworthy Machine Learning
T: Miscellaneous Aspects of Machine Learning
T: Social Aspects
DL: Robustness
2022 Poster
{kind=link}
Abstract
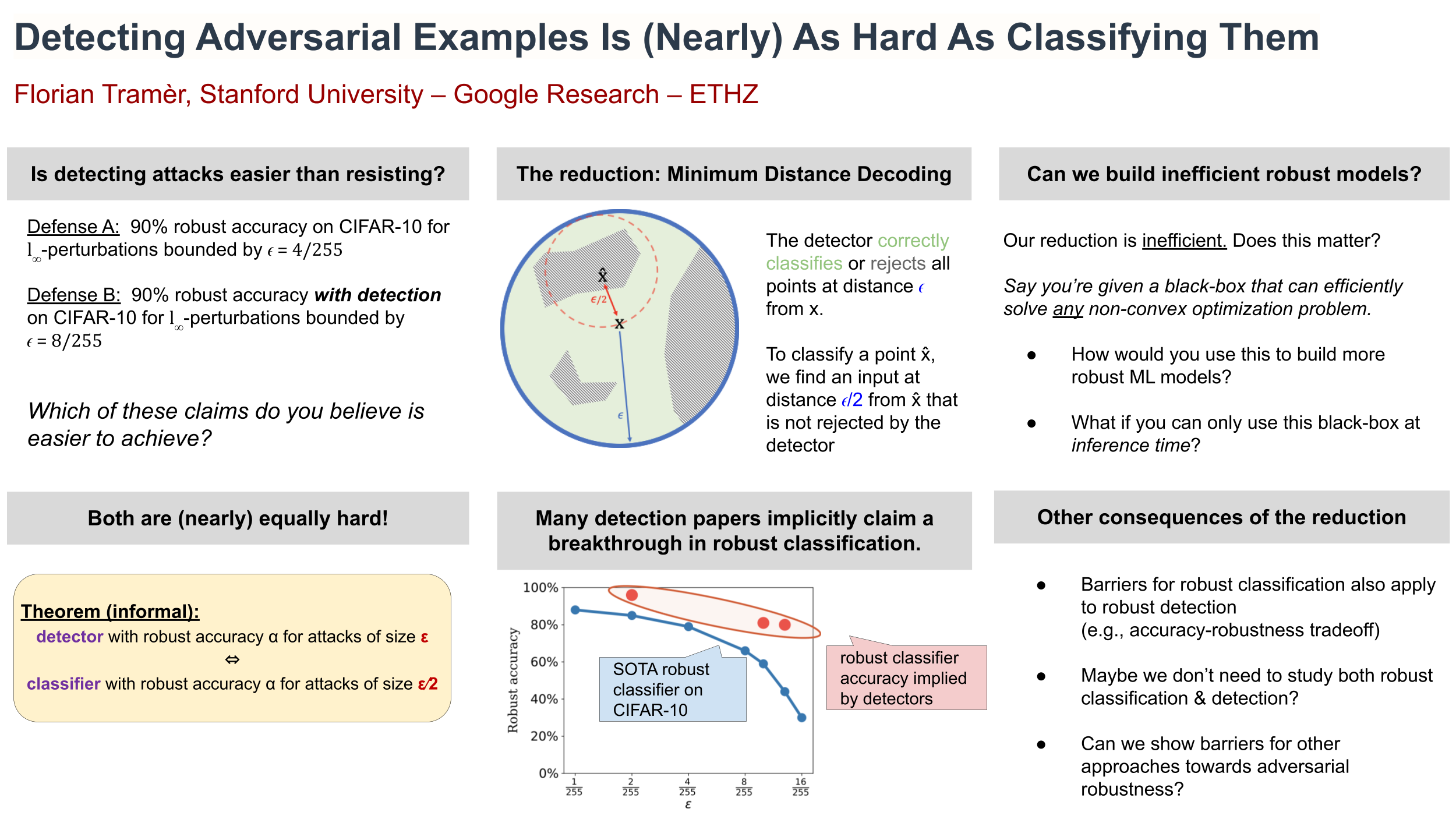
Making classifiers robust to adversarial examples is challenging. Thus, many works tackle the seemingly easier task of \emph{detecting} perturbed inputs.We show a barrier towards this goal. We prove a \emph{hardness reduction} between detection and classification of adversarial examples: given a robust detector for attacks at distance $\epsilon$ (in some metric), we show how to build a similarly robust (but inefficient) \emph{classifier} for attacks at distance $\epsilon/2$.Our reduction is \emph{computationally} inefficient, but preserves the \emph{data complexity} of the original detector. The reduction thus cannot be directly used to build practical classifiers.Instead, it is a useful sanity check to test whether empirical detection results imply something much stronger than the authors presumably anticipated (namely a highly robust and data-efficient \emph{classifier}).To illustrate, we revisit $14$ empirical detector defenses published over the past years. For $12/14$ defenses, we show that the claimed detection results imply an inefficient classifier with robustness far beyond the state-of-the-art--- thus casting some doubts on the results' validity.Finally, we show that our reduction applies in both directions: a robust classifier for attacks at distance $\epsilon/2$ implies an inefficient robust detector at distance $\epsilon$. Thus, we argue that robust classification and robust detection should be regarded as (near)-equivalent problems, if we disregard their \emph{computational} complexity.
Chat is not available.
Successful Page Load