On the Effects of Artificial Data Modification
{kind=link}
Abstract
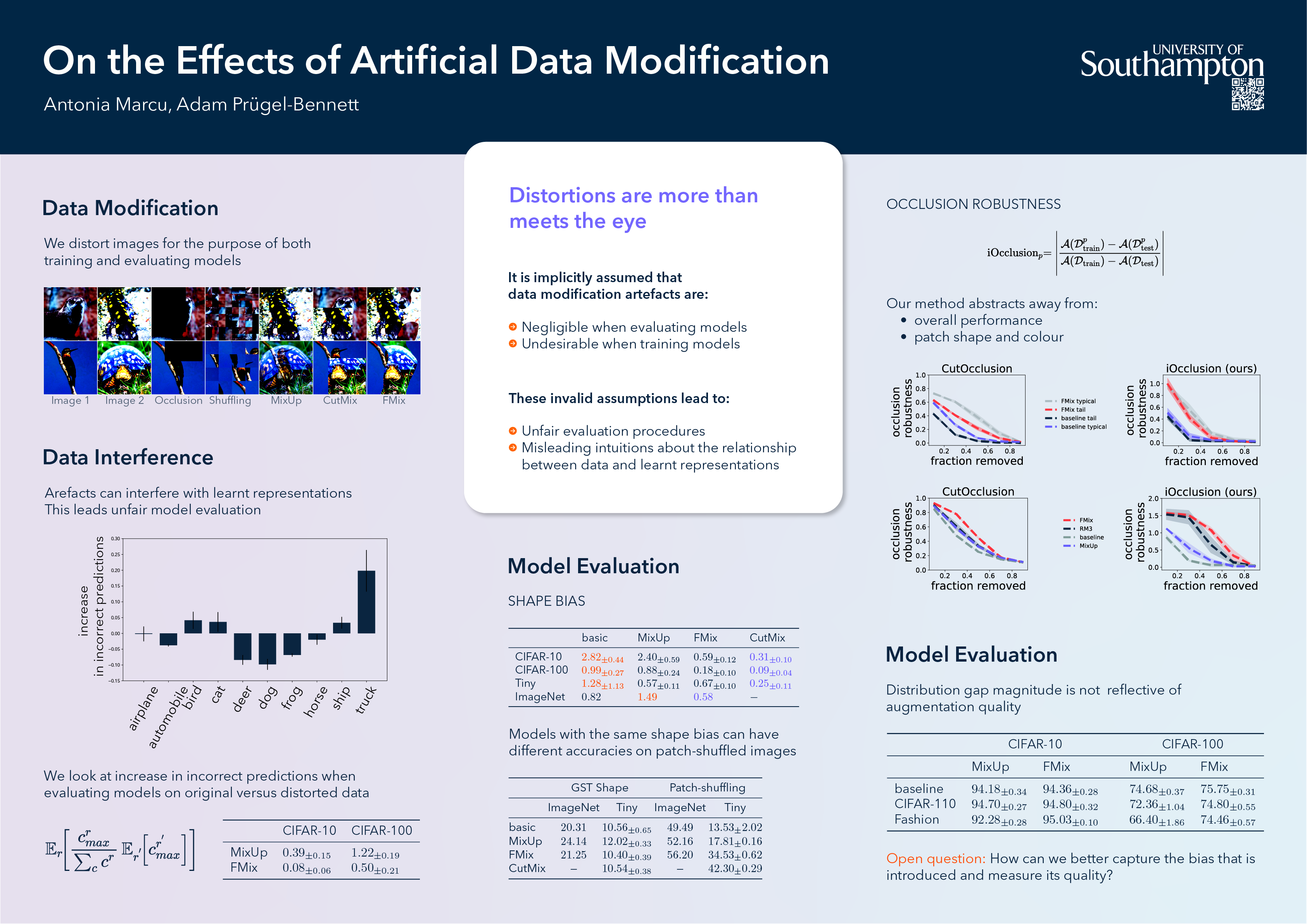
Data distortion is commonly applied in vision models during both training (e.g methods like MixUp and CutMix) and evaluation (e.g. shape-texture bias and robustness). This data modification can introduce artificial information. It is often assumed that the resulting artefacts are detrimental to training, whilst being negligible when analysing models. We investigate these assumptions and conclude that in some cases they are unfounded and lead to incorrect results. Specifically, we show current shape bias identification methods and occlusion robustness measures are biased and propose a fairer alternative for the latter. Subsequently, through a series of experiments we seek to correct and strengthen the community's perception of how augmenting affects learning of vision models. Based on our empirical results we argue that the impact of the artefacts must be understood and exploited rather than eliminated.