OOD-Chameleon: Is Algorithm Selection for OOD Generalization Learnable?
{kind=link}
Abstract
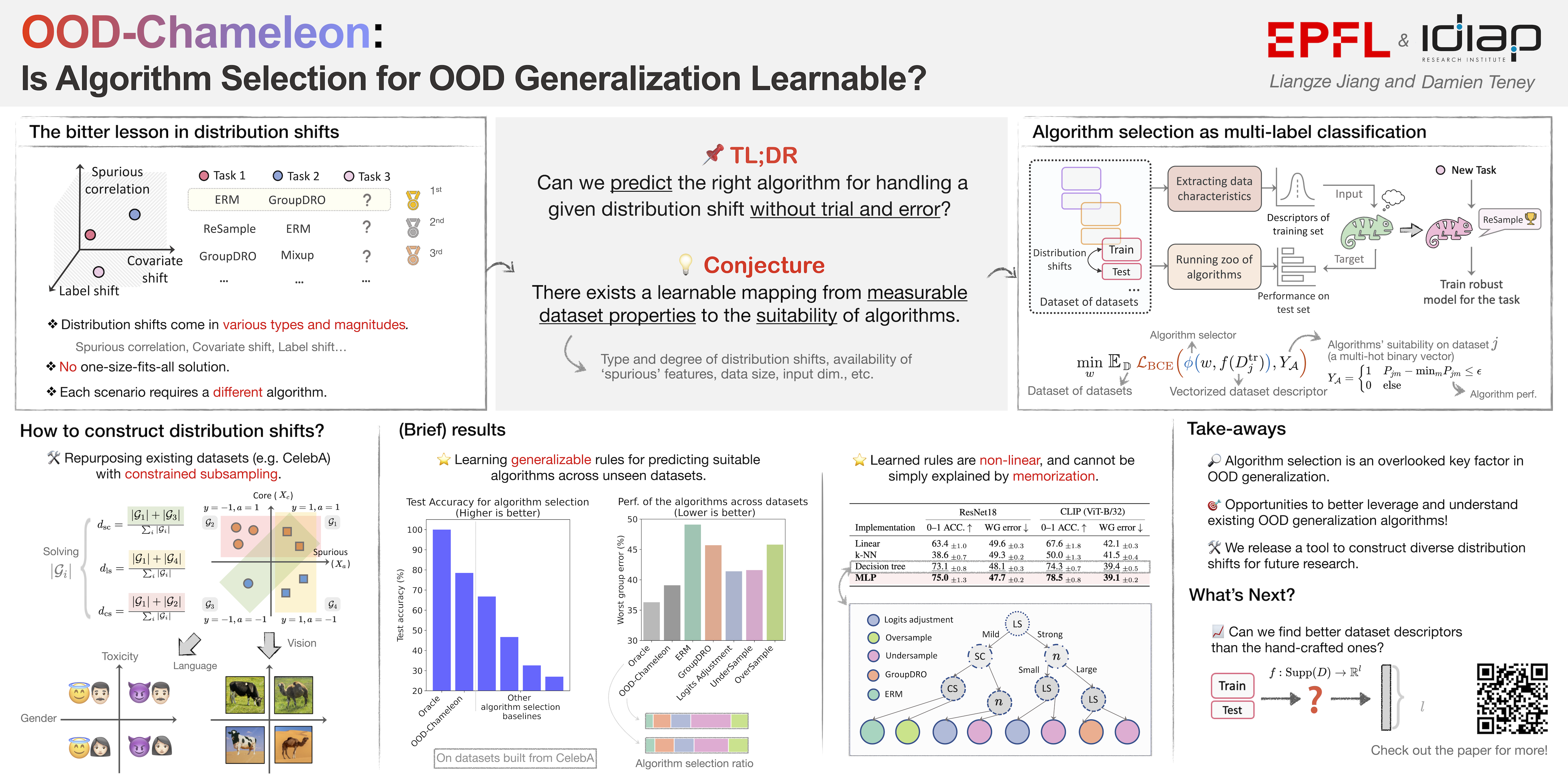
Out-of-distribution (OOD) generalization is challenging because distribution shifts come in many forms. Numerous algorithms exist to address specific settings, but choosing the right training algorithm for the right dataset without trial and error is difficult. Indeed, real-world applications often involve multiple types and combinations of shifts that are hard to analyze theoretically.Method. This work explores the possibility of learning the selection of a training algorithm for OOD generalization. We propose a proof of concept (OOD-Chameleon) that formulates the selection as a multi-label classification over candidate algorithms, trained on a dataset of datasets representing a variety of shifts. We evaluate the ability of OOD-Chameleon to rank algorithms on unseen shifts and datasets based only on dataset characteristics, i.e., without training models first, unlike traditional model selection.Findings. Extensive experiments show that the learned selector identifies high-performing algorithms across synthetic, vision, and language tasks. Further inspection shows that it learns non-trivial decision rules, which provide new insights into the applicability of existing algorithms. Overall, this new approach opens the possibility of better exploiting and understanding the plethora of existing algorithms for OOD generalization.
Lay Summary
Machine learning models often lose their predictive power when applied outside the distribution of their training data. Different forms of such scenarios, known as "distribution shifts" have been studied, and can be each addressed with specialized methods. However, identifying the right method for the right scenario typically requires guesswork and experimentation.This paper introduces an approach that automatically identifies which existing method to apply to a given use case that involves distribution shifts. Our approach, dubbed OOD-Chameleon, is itself a learned model, that we train on a collection of distribution shift scenarios generated semi-synthetically. We train this model to associate measurable properties of the data with suitable methods that can address the specific form(s) of distribution shift(s) present in the data. After this preparatory phase, our model can recommend a suitable method for a new use case that can produce a model with high robustness to the distribution shifts in this use case.Overall, this work provides a new approach to handling distribution shifts by adaptively leveraging the variety of already-existing methods. Moreover, it also provides new insights into the applicability of these existing methods that address the reliability of AI systems.