Tackling Dimensional Collapse toward Comprehensive Universal Domain Adaptation
{kind=link}
Abstract
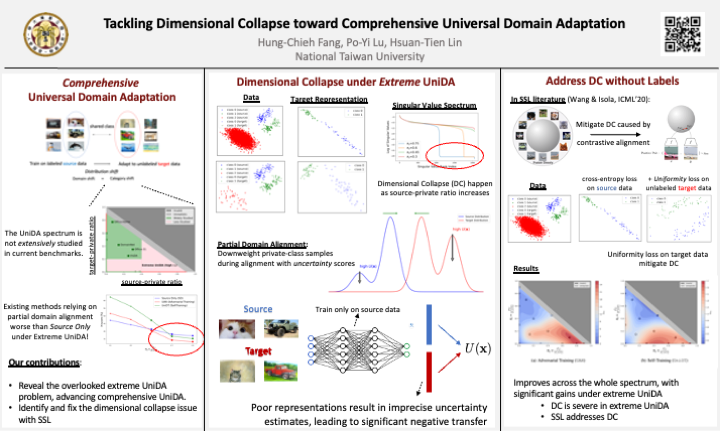
Universal Domain Adaptation (UniDA) addresses unsupervised domain adaptation where target classes may differ arbitrarily from source ones, except for a shared subset. A widely used approach, partial domain matching (PDM), aligns only shared classes but struggles in extreme cases where many source classes are absent in the target domain, underperforming the most naive baseline that trains on only source data. In this work, we identify that the failure of PDM for extreme UniDA stems from dimensional collapse (DC) in target representations. To address target DC, we propose to jointly leverage the alignment and uniformity techniques in self-supervised learning on the unlabeled target data to preserve the intrinsic structure of the learned representations. Our experimental results confirm that SSL consistently advances PDM and delivers new state-of-the-art results across a broader benchmark of UniDA scenarios with different portions of shared classes, representing a crucial step toward truly comprehensive UniDA. Project page: https://dc-unida.github.io/
Lay Summary
When training AI models to work well across different environments, a common challenge is that the categories the model sees during training (source domain) may not fully match those in the new environment (target domain). This problem is known as Universal Domain Adaptation (UniDA). A popular method tries to match only the overlapping categories between domains. However, in extreme cases—where most categories in the training data don't exist in the new environment—this method actually performs worse than doing nothing at all.We found that this failure is caused by something called dimensional collapse, where the model's understanding of the new environment becomes overly simplified and loses important detail. To fix this, we borrow techniques from self-supervised learning to help the model preserve the structure of the new environment’s data, even without labels.Our method consistently improves performance in a wide range of UniDA scenarios, setting new state-of-the-art results. This brings us one step closer to building AI systems that can truly adapt to real-world environments with unknown or shifting categories.