Learning to Reuse Policies in State Evolvable Environments
{kind=link}
Abstract
Lay Summary
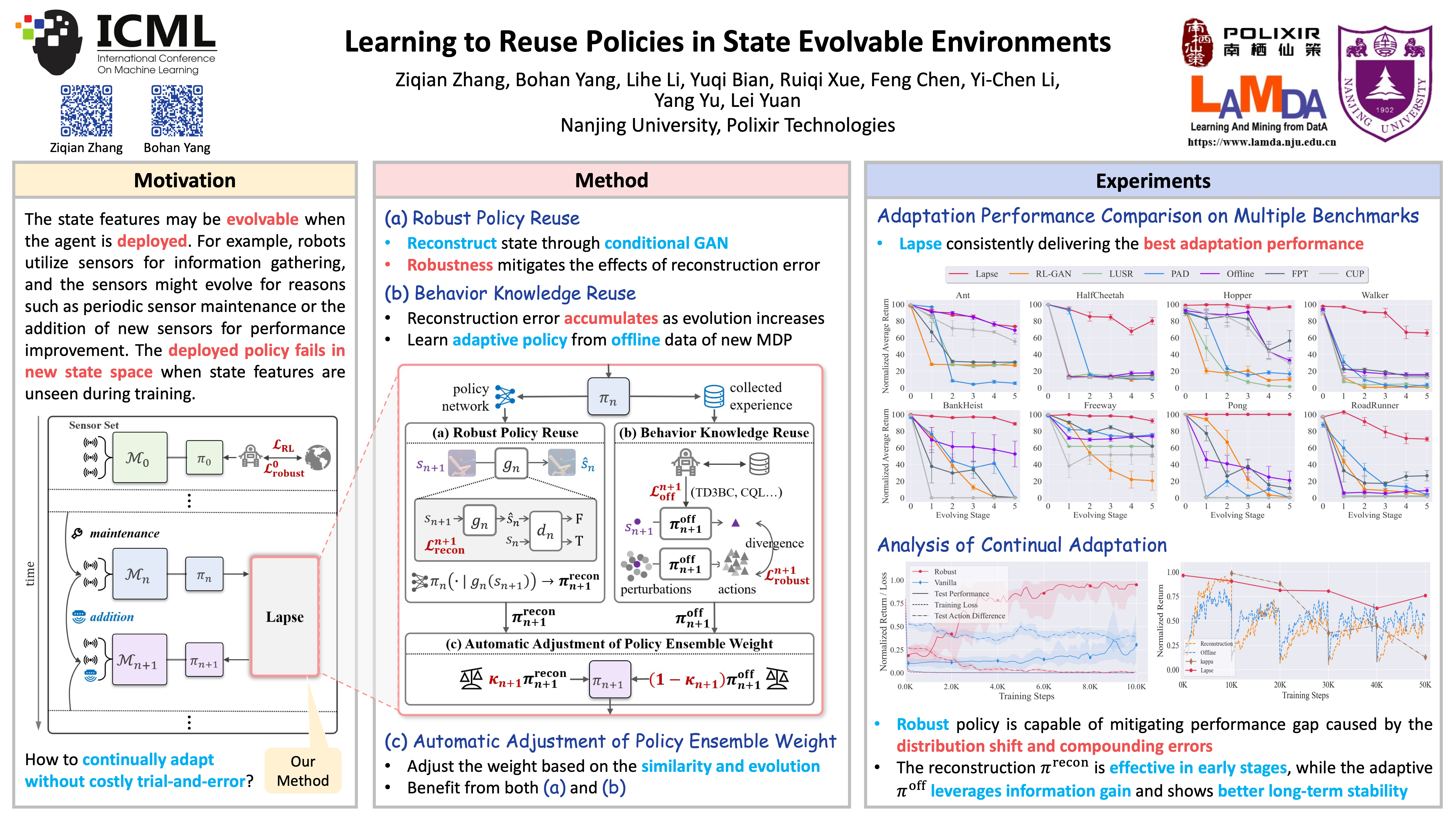
Many automated systems rely on sensor data to make decisions, but sensors can change over time—for example, due to maintenance or upgrades. When this happens, decision-making policies trained on old sensor data often experience a drop in performance, because they are not prepared for new or missing information.Previous solutions try to make policies ignore sensor differences or train several policies and pick the right one, but these approaches often struggle when facing unexpected sensor changes. To address this, we introduce a new framework called state evolvable reinforcement learning (SERL), which aims to maintain reliable performance even as sensors change, without costly trial-and-error.Our method, called Lapse, reuses knowledge from old sensor setups in two ways: it adapts the old policy to work with missing sensors and uses experience from the old setup to train a new, more adaptive policy for new sensors. Lapse can automatically combine both approaches depending on the situation. In tests, Lapse showed significantly better performance than previous methods, helping automated systems stay reliable as their sensors evolve.