Pivoting Factorization: A Compact Meta Low-Rank Representation of Sparsity for Efficient Inference in Large Language Models
{kind=link}
Abstract
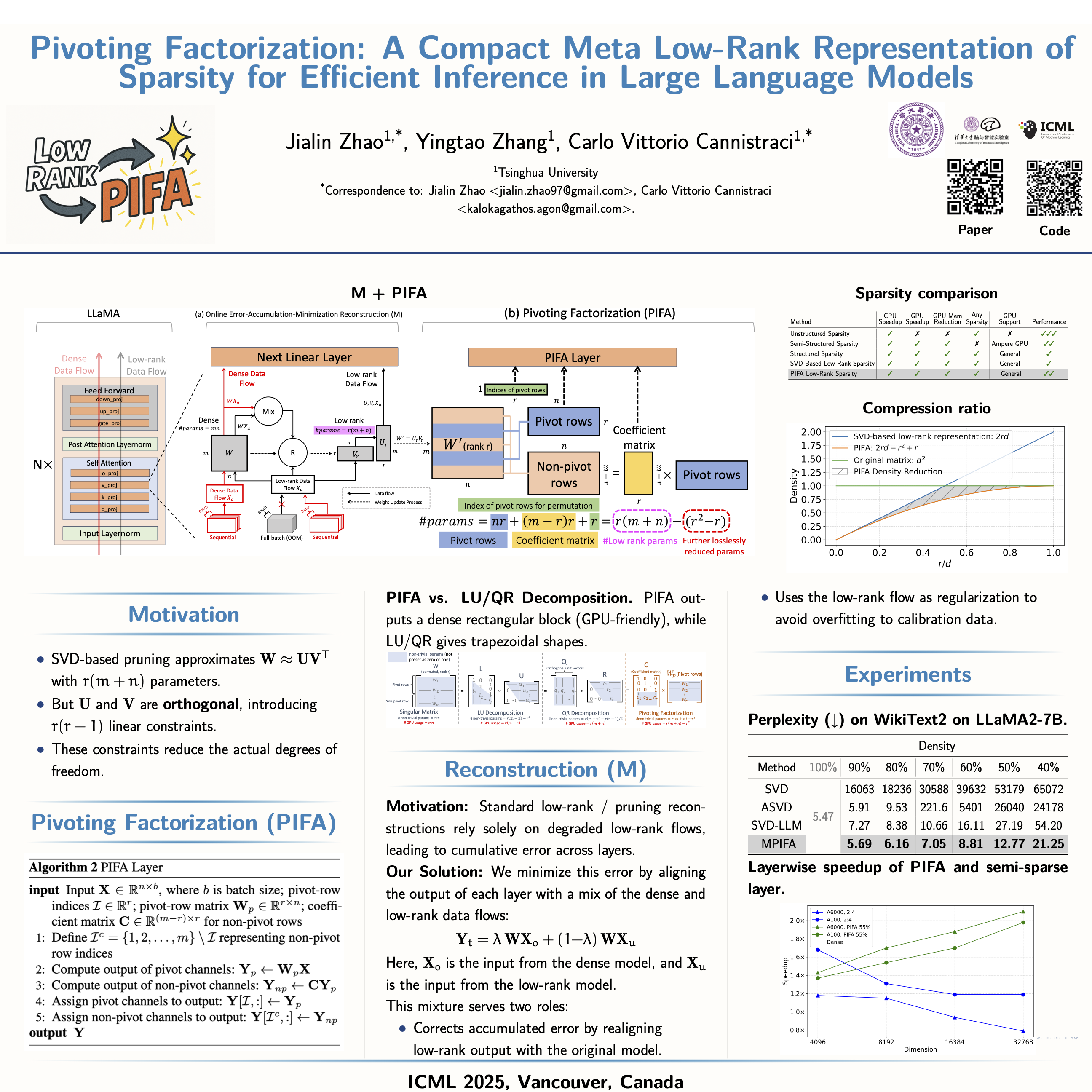
The rapid growth of Large Language Models has driven demand for effective model compression techniques to reduce memory and computation costs. Low-rank pruning has gained attention for its GPU compatibility across all densities. However, low-rank pruning struggles to match the performance of semi-structured pruning, often doubling perplexity at similar densities. In this paper, we propose Pivoting Factorization (PIFA), a novel lossless meta low-rank representation that unsupervisedly learns a compact form of any low-rank representation, effectively eliminating redundant information. PIFA identifies pivot rows (linearly independent rows) and expresses non-pivot rows as linear combinations, achieving 24.2\% additional memory savings and 24.6\% faster inference over low-rank layers at rank = 50\% of dimension. To mitigate the performance degradation caused by low-rank pruning, we introduce a novel, retraining-free reconstruction method that minimizes error accumulation (M). MPIFA, combining M and PIFA into an end-to-end framework, significantly outperforms existing low-rank pruning methods, and achieves performance comparable to semi-structured pruning, while surpassing it in GPU efficiency and compatibility. Our code is available at https://github.com/biomedical-cybernetics/pivoting-factorization.
Lay Summary
Large language models like ChatGPT are incredibly powerful but also massive, requiring enormous memory and computation to run. Compressing these models helps make them faster and cheaper to use, but current techniques either depend on specialized hardware or lead to worse performance. Our research introduces a new compression method called MPIFA, which combines two ideas: a reconstruction method that prevents errors from piling up, and a new matrix math technique (called pivoting factorization) that removes hidden redundancies in compressed model layers—without losing information. Unlike existing methods, MPIFA works on any hardware and maintains the model’s performance while significantly improving memory and speed. We tested MPIFA on popular models like LLaMA and found that it matches the performance of specialized pruning techniques, while running faster and using less memory. This means AI models could soon become more accessible and efficient across a wide range of devices, from laptops to data centers.