Vision-Language Models Create Cross-Modal Task Representations
{kind=link}
Abstract
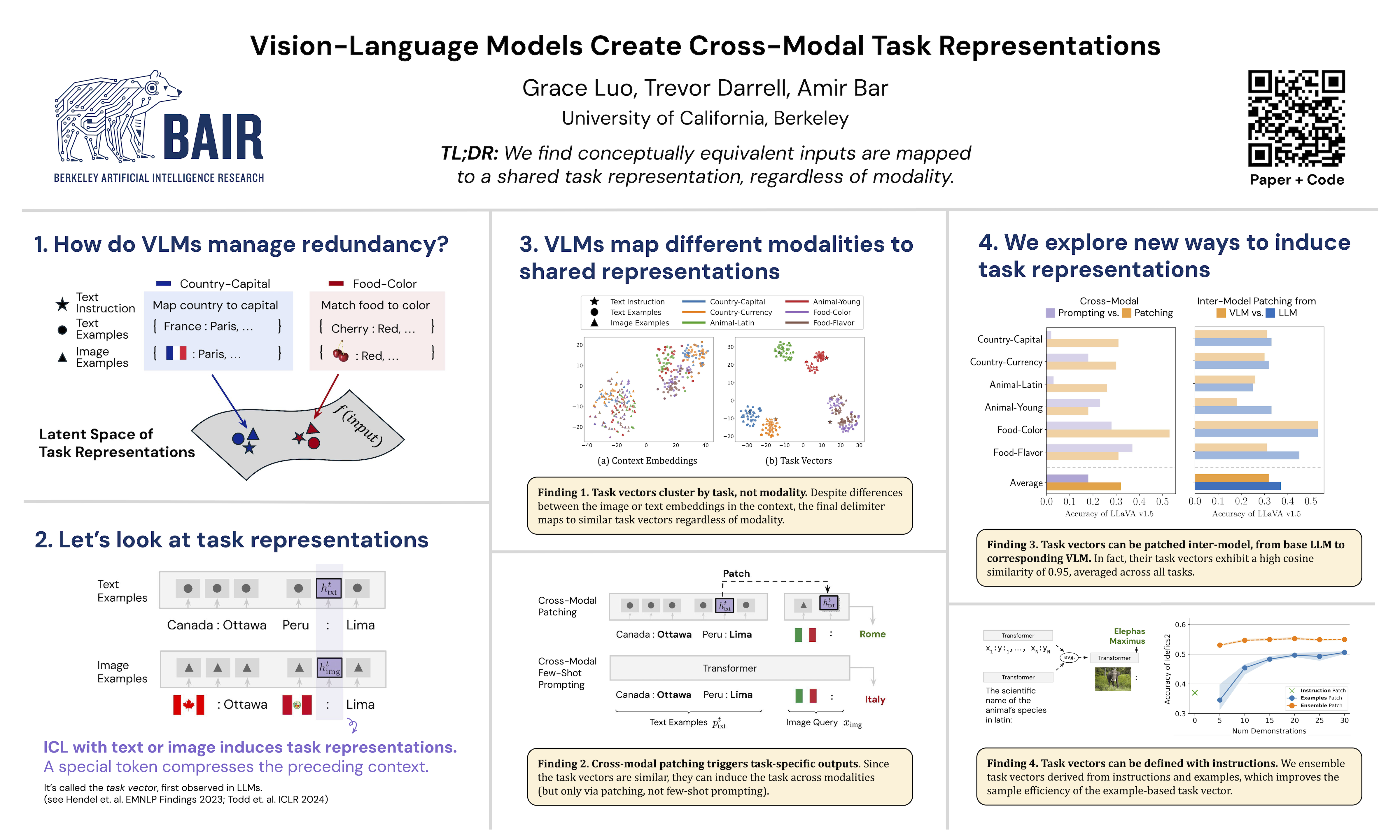
Autoregressive vision-language models (VLMs) can handle many tasks within a single model, yet the representations that enable this capability remain opaque. We find that VLMs align conceptually equivalent inputs into a shared task vector, which is invariant to modality (text, image) and format (examples, instruction), and may simplify VLM processing. We measure this alignment via cross-modal transfer--the ability of a task vector derived in one modality to trigger the correct generation in another--on a range of tasks and model architectures. Although the task vector is highly compressed, we find that this single vector outperforms prompting the model with the full task information, unique to this cross-modal case. Furthermore, we show that task vectors can be transferred from a base language model to its fine-tuned vision-language counterpart, and that they can be derived solely from instructions without the need for examples. Taken together, our findings shed light on how VLMs internally process task information, and how they map different modalities into common semantic representations.
Lay Summary
Vision-language models, or VLMs, are a class of models that process images based on user prompts. This means that VLMs can handle many computer vision tasks simply by adjusting the prompt, but we don't understand how they internally route what task to do based on the inputs.We find that VLMs encode tasks in a representation space that is shared across text and images. For example, we show it is possible to define a task with text examples and use that same representation to trigger the model to perform the same task on an image query. Even more surprisingly, we show that representations from the base language model (from which the VLM was initialized) can trigger the same behavior in the vision-language model. Taken together, our findings shed light on how VLMs internally process task information, and how they map different modalities into common semantic representations.