LaRA: Benchmarking Retrieval-Augmented Generation and Long-Context LLMs – No Silver Bullet for LC or RAG Routing
{kind=link}
Abstract
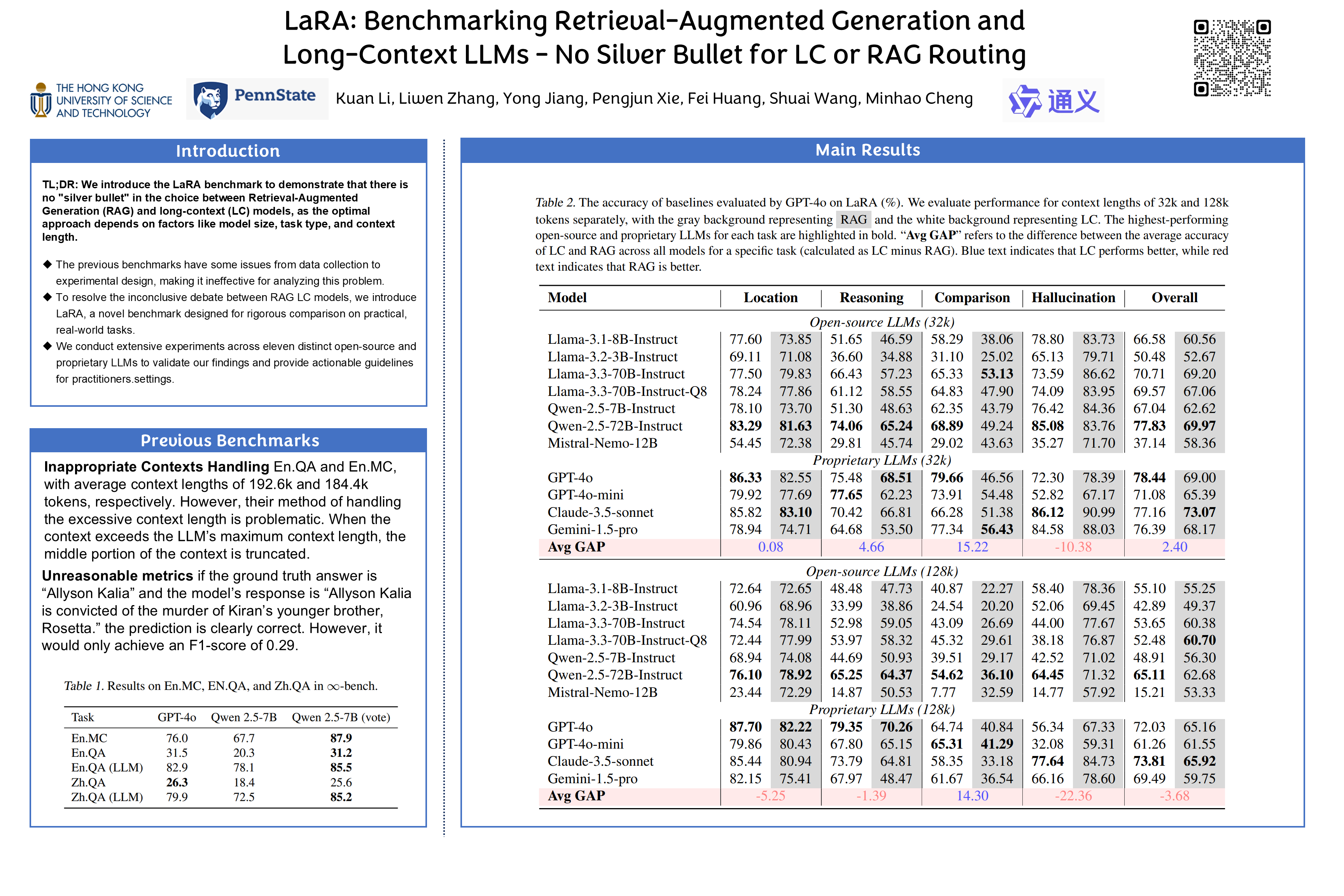
As Large Language Model (LLM) context windows expand, the necessity of Retrieval-Augmented Generation (RAG) for integrating external knowledge is debated. Existing RAG vs. long-context (LC) LLM comparisons are often inconclusive due to benchmark limitations. We introduce LaRA, a novel benchmark with 2326 test cases across four QA tasks and three long context types, for rigorous evaluation. Our analysis of eleven LLMs reveals the optimal choice between RAG and LC depends on a complex interplay of model capabilities, context length, task type, and retrieval characteristics, offering actionable guidelines for practitioners. Our code and dataset is provided at:https://github.com/Alibaba-NLP/LaRA
Lay Summary
(1) When a user asks a question based on a long text, should we have the LLM answer directly using the full context, or should we retrieve only the chunks relevant to the query using certain rules or similarity detection? (2) To answer this question, we propose LaRA, a comprehensive benchmark specifically designed to compare long-context LLMs and Retrieval-Augmented Generation (RAG). (3) We find that neither RAG nor long-context LLMs are a silver bullet; their relative strengths and weaknesses depend on a wide range of factors.