PhantomWiki: On-Demand Datasets for Reasoning and Retrieval Evaluation
{kind=link}
Abstract
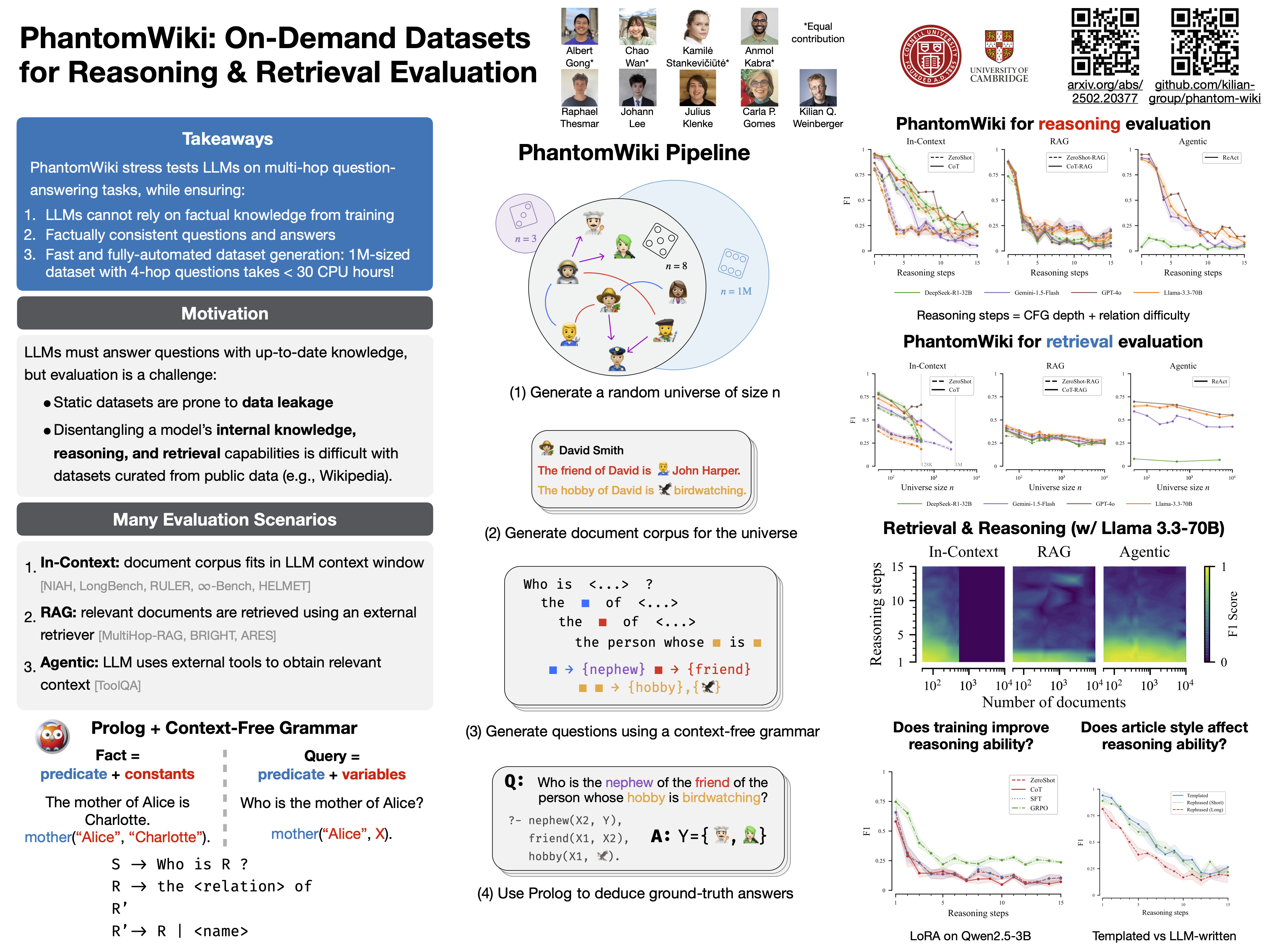
High-quality benchmarks are essential for evaluating reasoning and retrieval capabilities of large language models (LLMs). However, curating datasets for this purpose is not a permanent solution as they are prone to data leakage and inflated performance results. To address these challenges, we propose PhantomWiki: a pipeline to generate unique, factually consistent document corpora with diverse question-answer pairs. Unlike prior work, PhantomWiki is neither a fixed dataset, nor is it based on any existing data. Instead, a new PhantomWiki instance is generated on demand for each evaluation. We vary the question difficulty and corpus size to disentangle reasoning and retrieval capabilities, respectively, and find that PhantomWiki datasets are surprisingly challenging for frontier LLMs. Thus, we contribute a scalable and data leakage-resistant framework for disentangled evaluation of reasoning, retrieval, and tool-use abilities.
Lay Summary
High-quality datasets are essential for comprehensive evaluation of large language models (LLMs), such as ChatGPT and Claude. However, as models learn from the whole of internet’s data, there is a risk that the models get exposed to such evaluation datasets and subsequently “cheat” by providing memorized answers instead of actually going through the “thinking” process.We present a methodology to programmatically generate unique datasets of articles and question-answer pairs. The nature of this process ensures that every time evaluation is needed, we can generate a new dataset instance that the model has not seen before (and therefore finds it hard to “cheat” on), while at the same time ensuring that the questions are difficult and the true answers are consistent with the data. We show that, as the number of documents and the question difficulty increase, frontier LLMs struggle to find the correct answers, demonstrating the limitations in their abilities to reason and find relevant information among a large set of documents.