QUTE: Quantifying Uncertainty in TinyML models with Early-exit-assisted ensembles for model-monitoring
{kind=link}
Abstract
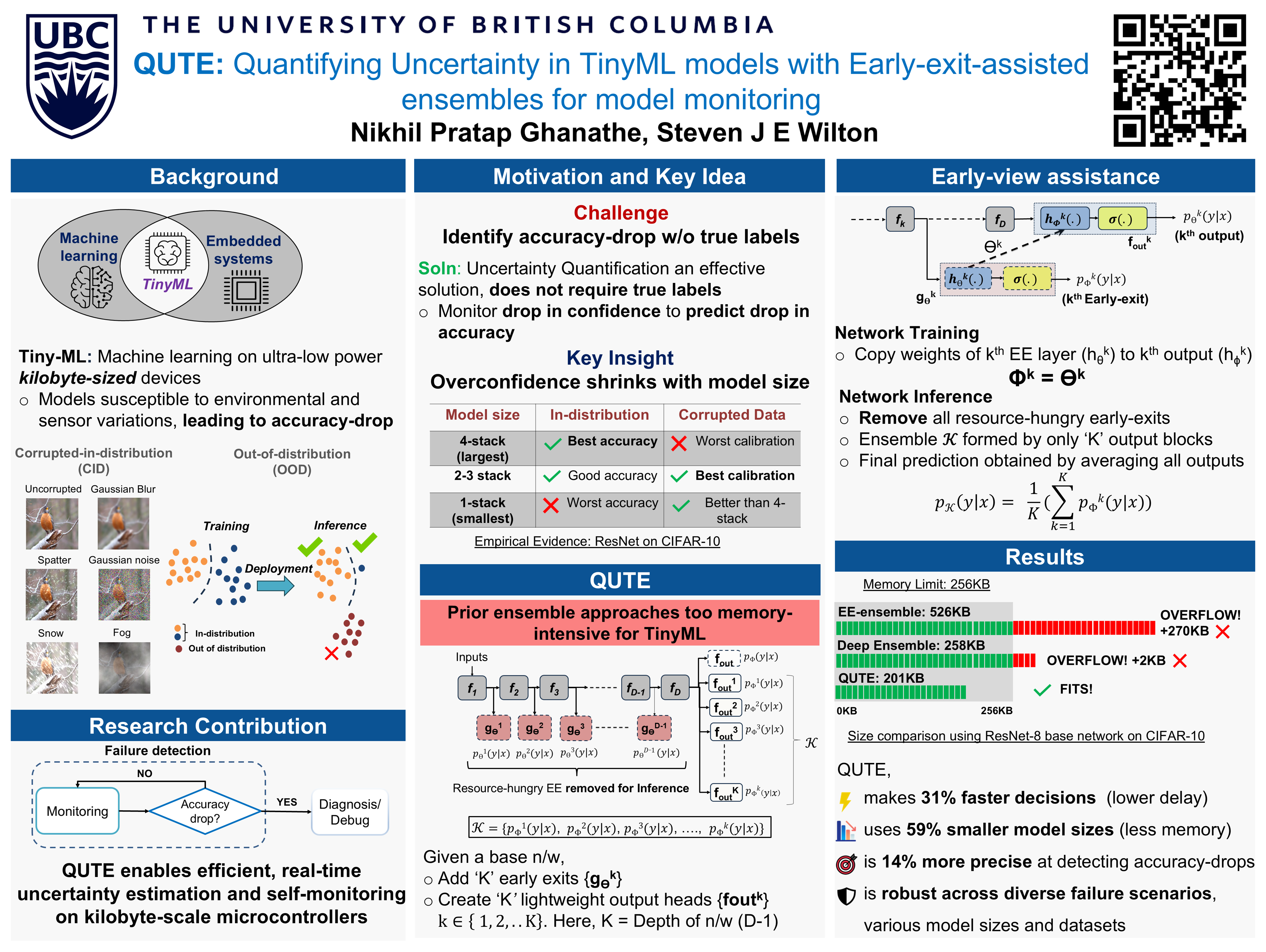
Uncertainty quantification (UQ) provides a resource-efficient solution for on-device monitoring of tinyML models deployed remotely without access to true labels. However, existing UQ methods impose significant memory and compute demands, making them impractical for ultra-low-power, KB-sized tinyML devices. Prior work has attempted to reduce overhead by using early-exit ensembles to quantify uncertainty in a single forward pass, but these approaches still carry prohibitive costs. To address this, we propose QUTE, a novel resource-efficient early-exit-assisted ensemble architecture optimized for tinyML models. QUTE introduces additional output blocks at the final exit of the base network, distilling early-exit knowledge into these blocks to form a diverse yet lightweight ensemble. We show that QUTE delivers superior uncertainty quality on tiny models, achieving comparable performance on larger models with 59% smaller model sizes than the closest prior work. When deployed on a microcontroller, QUTE demonstrates a 31% reduction in latency on average. In addition, we show that QUTE excels at detecting accuracy-drop events, outperforming all prior works.
Lay Summary
Tiny AI models, known as TinyML, are being used in everything from wearable health monitors to environmental sensors. These models run directly on low-power devices — often no bigger than a coin — and help make fast decisions without needing to send data to the cloud. But there’s a problem: how do we know when these tiny models are making a mistake, especially when they’re deployed in remote or hard-to-reach places with no cloud access or human supervision?That’s where QUTE comes in. QUTE is a new technique we’ve developed to help tiny AI models recognize when they’re uncertain — in other words, when their predictions might be wrong. This ability to estimate confidence (called uncertainty quantification) is crucial for safety, reliability, and smart decision-making in the field. Unlike other methods that are too large or slow for tiny devices, QUTE is designed to work efficiently on ultra-low-power hardware.It works by adding small "checkpoints" inside the model and training lightweight prediction blocks that each learn something different. Together, they act like a mini-team of experts that can double-check each other’s confidence and flag when the model might be unsure — all without taking up much space or time.In real-world tests, QUTE made decisions faster (31% lower delay), used less memory (59% smaller), and was better at spotting problems compared to previous approaches. This makes QUTE a strong choice for making AI on tiny devices both faster and more trustworthy.